Helló.
Egy olyan problémáról szeretnék beszélni, amely akkoriban nagyon érdekelt, mégpedig az idősorok előrejelzésének problémájáról, és ennek a probléma megoldásának a hangyatelepi algoritmussal.
Kezdésként röviden a problémáról és magáról az algoritmusról:
Az idősoros előrejelzés azt jelenti, hogy az idősor első n pontjában valamely függvény értéke ismert. Ezen információk felhasználásával meg kell jósolni az idősor n + 1 pontján lévő értéket. Sokféle előrejelzési módszer létezik, de ma a Winters-módszer és az ARIMA modell a legelterjedtebbek közé tartozik. Bővebben olvashatsz róluk.
Sok szó esett már arról, hogy mi is az a hangyatelep-algoritmus. Azok számára, akik lusták mászni, pl. itt, elmesélem. Röviden, a hangya-algoritmus egy hangyakolónia viselkedésének szimulációja, amikor a táplálékforráshoz vezető legrövidebb utat keresik. A hangyák mozgásuk során feromonnyomot hagynak maguk után, ami befolyásolja annak valószínűségét, hogy a hangya egy adott utat választ. Figyelembe véve, hogy a hangyák ugyanannyi idő alatt többször is átmennek a rövid úton, több feromon marad rajta. Így az idő múlásával egyre több hangya választja a legrövidebb utat táplálékforrásához.
Az érthetőség kedvéért beszúrok egy képet:
Most menjünk közvetlenül a hangyatelep módszerrel történő előrejelzés problémájának megoldásához.
Az első probléma, amivel szembesülünk, az, hogy az idősort grafikonként kell ábrázolni, amelyen lefuttatjuk a hangyatelep algoritmust.
Két lehetséges megoldás született:
1. Ábrázolja az idősort multigráfként, ahol az idősorok minden pontjáról bizonyos lépésekben mindegyikhez eljuthat. (A feladat megkönnyítése érdekében normalizált értékeket veszünk a -1 és 1 közötti intervallumban). Ez volt az első megközelítés, amit kipróbáltunk. Alacsony dimenziós idősorokon jó eredményt mutatott, de a dimenzió növekedésével mind az előrejelzés pontossága, mind a teljesítmény meredeken csökkenni kezdett, ezért ezt a lehetőséget elhagyták.
2. Ábrázolja az idősort összekapcsolt grafikonok halmazaként, ahol minden grafikon saját maga felelős az idősor értékének növekedéséért. más szóval, van egy grafikonunk, amely felelős a -1, -0,9 ... és így tovább 1-ig történő növekedésért. A lépés természetesen csökkenthető vagy növelhető, ami befolyásolja az előrejelzés pontosságát és a feladat erőforrás-intenzitása. (Végül ez a lehetőség bizonyult a legsikeresebbnek.)
Ezen a kapcsolt gráfkészleten elindult egy hangyatelep-algoritmus (minden gráfnak megvan a maga sajátja), amely az idősor ismert értékeinek megfelelő élekre helyezte a feromont. Sőt, amikor a feromon lerakódott az i gráfra, a feromon az i-1 és i+1 gráfokra is lerakódott, de jóval kisebb mennyiségben (esetünkben a feromon alapmennyiségének 1/10-e), így a hangyák azonosították az ideiglenes sorozatok értékének növekedésének leggyakoribb sorozatait, és a feromon szomszédos grafikonokra való halasztása miatt az idősorok lehetséges hibája és kezdeti zajossága kiegyenlítődött.
Ezt az algoritmust mesterségesen készített, különböző periodicitási és zajszintű idősorokon teszteltük. Az eredmény kettős. Egyrészt 0,3-ig terjedő zajszinten az algoritmus az ARIMA modell eredményeihez hasonló magas előrejelzési eredményeket mutat. Magasabb zajszinteknél az eredmények nagy szóródást mutatnak: az előrejelzés vagy nagyon pontos, vagy teljesen téves.
Jelenleg az algoritmus paramétereinek optimális értékének kiválasztásán és néhány javítási módszerén dolgozunk, amelyekről amint kellően teszteltek, írok.
Köszönöm mindenkinek a figyelmet.
Frissítés: Megpróbálok válaszolni a felmerült kérdésekre.
A multigráf olyan gráf, amelyben minden csúcs minden egyes csúcshoz kapcsolódik.
A kaotikus sorozatok, ahogy az alábbiakban már említettük, nem véletlenszerűek. Megtekintheti a Lorenz sorozat képeit 3 dimenziós térben, és láthatja a ciklikus mozgást. Ezt a ciklikusságot nehéz egyszerűen meghatározni, és első pillantásra a sorozat véletlenszerűnek tűnik.
Az idősorok értékeit a -1...1 intervallumban normalizáljuk és a grafikonon rögzítjük. Grafikon - ebben az esetben a csúcsról a csúcsra való átmenetek táblázata. A feromon a bordákon (a táblázat celláiban) rakódik le.
Kapcsolt gráfok esetén több táblázatot használnak, amelyek mindegyike csak a saját átmeneti értékéért felelős.
Az adott sejtben lévő feromon mennyiségétől függően az idősor egyik vagy másik értéke az előrejelzés eredményeként kerül kiválasztásra.
Az algoritmust főleg a Lorenz sorozaton tesztelték.
Jelenleg még korai megmondani, mennyivel jobb vagy rosszabb. Úgy tűnik, hogy az algoritmus hajlamos pszeudo-periódusokat találni, és a zajszint növekedésével nő a hamis periódusok száma.
Ezzel szemben a paraméterek sikeres megválasztása mellett az előrejelzés pontossága meglehetősen nagy (akár 7-10 százalékos is lehet az eltérés, ami nem rossz egy kaotikus sorozatnál).
Később áttérünk a valós adatokon végzett tesztelésre. A közeljövőben igyekszem felkészülni és képeket csatolni.
Köszönöm a figyelmet.
Az idősorelemzés (TSA) a függőség helyreállításának legegyszerűbb módszere determinisztikus esetben, adott idősor alapján. A fő feladat az extrapoláció (előrejelzés) – a piaci helyzet előrejelzésének legegyszerűbb módja. Lényege a múltban és a jövőben kialakult irányzatok terjesztése.
Sok piaci folyamatnak van tehetetlensége, amit az előrejelzéseknél figyelembe vesznek. Egy bizonyos időszakra a lehető legnagyobb mértékben figyelembe kell venni a piaci feltételek változásának valószínűségét. Feltételezhető, hogy a rendszer meglehetősen stabil körülmények között fejlődik. Minél nagyobb a rendszer, annál valószínűbb, hogy a paraméterek változatlanok maradnak, de nem sokáig. Javasoljuk, hogy az előrejelzési időszak ne haladja meg az eredeti időalap hosszának 1/3-át.
Idősorok - szabályos időközönként kapott számértékek sorozata Az idősorok vállalkozásban történő felhasználásának fő feltételezése az, hogy a vizsgált rendszer reakcióját befolyásoló tényezők a múltban, jelenben és hasonlóképpen fog eljárni a közeljövőben.
Az elemzés célja a tényezők értékelése és azonosítása a rendszer további viselkedésének előrejelzése és a racionális SD kialakítása érdekében. Az ATS-en alapuló előrejelzés rövid távú, az időszakhoz viszonyítva, ami elfogadott, a vizsgált jelenség jellemzői lényegesen nem változnak. A legtöbb előrejelzési hiba abból adódik, hogy az előrejelzés a múltbeli trendek jövőbeli folytatódását feltételezi. Ez a hipotézis a gazdasági és társadalmi életben ritkán igazolódik.
A VR rossz alap lehet az előrejelzés elkészítéséhez, ezért az előrejelzési módszereket és az AVR-t meglehetősen stabil és jól tanulmányozott folyamatok rövid távú előrejelzésére használják. Az előrejelzési időszak nem haladja meg az eredeti időalap 25-30%-át. A regressziós egyenlet használatakor prediktív számításokat végeznek a kezdeti paraméterek optimista és pesszimista becslésére. Innen 2 típusú előrejelzést kapunk: optimista és pesszimista. A predikciós módszerekkel kapott prediktív pontszámot a prediktív paraméter kívánt értékének mutatójaként használják.
A VR a következőket tartalmazza:
1) trend - mutatja a változás általános típusát, a sorozat hosszú távú csökkenését és növekedését,
2) szezonális ingadozások - a trend körüli ingadozások, amelyek rendszeresen előfordulnak.
Rendszeres ingadozások jellemzően legfeljebb egy éven belül jelentkeznek. Nyomon követhető negyedévente, havonta, hetente stb. megfigyelések.
3) ciklikus ingadozások - egy éven túli időszakokban fordulnak elő. Gyakran jelen van a pénzügyi adatokban, és meredek hanyatlással, gyors növekedéssel és stagnálási időszakkal társul.
4) véletlenszerű ingadozások – előre nem látható ingadozások a legtöbb valós VR-ben.
Az idősoros adatokra vonatkozó követelmények
Valamennyi előrejelzési módszer matematikai statisztikát használ, ezért szükséges, hogy minden adat összehasonlítható, kellően bemutatható legyen az egységes és stabil minták megnyilvánulásához. E követelmények valamelyikének elmulasztása értelmetlenné teszi a matematikai statisztikák használatát.
1. Összehasonlíthatóság az idősor kialakításának különböző szakaszaiban végzett megfigyelések azonos megközelítésének eredményeként érhető el. Az idősorok adatait azonos mértékegységekben kell kifejezni, azonos megfigyelési lépésekkel kell rendelkezni, ugyanarra az időintervallumra kell számítani azonos módszertannal, ugyanazokat az azonos területhez tartozó és ugyanahhoz a sokasághoz kapcsolódó elemeket kell lefedni.
Az adatok összeférhetetlensége leggyakrabban költségmutatókban nyilvánul meg. Még azokban az esetekben is, amikor ezeknek a mutatóknak az értékei változatlan áron vannak rögzítve. Az idősorok ilyen jellegű összeegyeztethetetlensége pusztán formális módszerekkel nem küszöbölhető ki.
2. Az adatok reprezentativitása elsősorban a bemutatott adatok teljessége jellemzi. A vizsgálat céljától függően elegendő számú megfigyelést határoznak meg. Ha a cél a leíró statisztikai elemzés, akkor a vizsgált időintervallumnak tetszőleges időintervallum választható. Ha a vizsgálat célja előrejelzési modell felépítése, akkor a kezdeti idősorokban az adatok száma az előrejelzési periódus legalább háromszorosa legyen, és nem lehet kevesebb 7 adatnál. A szezonalitás vizsgálatára és a szezonális folyamatok előrejelzésére negyedéves vagy havi adatok felhasználása esetén a kezdeti idősornak legalább 4 évre vonatkozó negyedéves vagy havi adatokat kell tartalmaznia, még akkor is, ha 1 vagy 2 hónapos előrejelzés szükséges.
3.Egyöntetűség- az atipikus rendellenes megfigyelések hiánya, valamint a trendek (változás) megszakadása. Az anomália a becslések torzulásához vezet, és ennek eredményeként az elemzési eredmények torzulásához vezet. Formálisan egy anomália erős ugrásként vagy hanyatlásként nyilvánul meg, amelyet az előző szint hozzávetőleges helyreállítása követ. Különféle standard kritériumokat dolgoztak ki az anomális megfigyelések diagnosztizálására.
4. Fenntarthatóság- ez a tulajdonság a szabályszerűség túlsúlyát tükrözi a véletlenszerűséggel szemben a szintek és sorozatok változásaiban. A stabil idősorok diagramjain még vizuálisan is nyomon követhető a szabályszerűség. Az instabil idősorok diagramjain pedig kaotikusan jelennek meg a változások. Ezért nincs értelme az ilyen idősorokban a minták keresésének.
Idősoros modellek
A statisztikai kutatási módszerek azon a feltételezésen alapulnak, hogy lehetséges egy idősor értékeit több komponens kombinációjaként ábrázolni, tükrözve a fejlődés szabályszerűségét és véletlenszerűségét. Különösen az additív (adaptív) és multiplikatív modelleket használják a rövid távú előrejelzésekhez.
1. Adaptív (additív)
Y(t) = T(t) + S(t) + F(t)
t - időintervallum száma
T(t) – fejlődési trend (hosszú távú trend)
S(t) - szezonális komponens
Е(t) – maradék komponens
2. Multiplikatív
I(t) = T(t)*S(t)*F(t)
Ha a szezonális hullám amplitúdója egyerős, akkor célszerű additív modellt használni. A szezonális hullám amplitúdójának megváltoztatásakor egy multiplikatív modellt alkalmazunk, hogy megfeleljen az átlagos szint trendjének. Néha alkalmaznak vegyes típusú modelleket, amelyek pontosabb eredményt adnak, de tartalmilag rosszul értelmezhetők. A multiplikatív modell alkalmazása annak köszönhető, hogy egyes idősorokban a szezonális komponens értéke a trendérték bizonyos hányadát képviseli. A gyakorlat azt mutatja, hogy azokban az esetekben, amikor a vizsgált folyamat szezonális ingadozásai nagyok és nem túl stabilak, a multiplikatív modell gyenge eredményeket ad. A szezonális komponens a szintek stabil és éven belüli ingadozásait jellemzi - néhány negyedéves vagy havi adatok által bemutatott mutatóban nyilvánul meg.
Az additív és multiplikatív komponenseket tartalmazó modellekben az általános elemzési eljárás megközelítőleg azonos.
Meg kell tenni:
1) a szezonális komponens értékeinek kiszámítása
2) a szezonális komponens levonása a tényleges értékekből - ezt a folyamatot szezonalizációnak (szezonalitás megszüntetésének) nevezik.
3) a hibák kiszámítása a tényleges és a trendértékek különbségeként
4) az átlagos eltérés vagy standard hiba kiszámítása
Előrejelzést is használnak növekedési görbe modellek.
A növekedési görbék olyan matematikai függvények, amelyeket egy idősor analitikus igazítására terveztek.
A következő függvények a növekedési görbék leírására szolgálnak
2. Y(t) parabola = a+bt =ct 2
3. Y(t) hiperbola = a + b/t
4. Hatalom
5. Bemutató
6. Logaritmikus
7. Johnson-görbe
8. Módosított kiállító
Idősor simítás
A fő fejlődési irányzat azonosítását az idősorok kiegyenlítésének vagy simításának nevezzük. A fő trend azonosításának módszerei a kiegyenlítési módszerek.
Az egyik legegyszerűbb módszer a jelenség fejlődésének általános trendjének kimutatására a dinamikus sorozatok intervallumának növelése. A fejlődési trendek azonosítására a mozgóátlagos módszert vagy az exponenciális simítási módszert alkalmazzuk. Mindkét módszer szubjektív a simítási paraméterek kiválasztását illetően. És a paraméterek helyes megválasztásában nyilvánul meg a kutató intuíciója.
mozgóátlag módszer– rendkívül szubjektív és a simítás eredményét erősen befolyásolja a simítási időszak hossza. Rövid időszakokkal nem lehet azonosítani a trendkomponenst. Nagy időszakok esetén jelentős adatvesztés következik be az elemzett intervallum végén.
Az L sorrendű mozgóátlag egy idősor, amely L számtani és számtani átlagból áll az Y függvény szomszédos értékeiben az összes lehetséges időértéken. Mint L - páratlan szám, 3, 5,7 - hárompontos, ötpontos és hétpontos.
Hárompontos séma: az átlagértéket 3 Yi érték alapján számítjuk ki, amelyek közül az egyik az elmúlt időszakra, a második a kívánt időszakra, a 3 pedig a jövőbeli időszakra vonatkozik. Ha i = 1 nincs múltbeli érték, akkor az első pontban nem lehet kiszámítani a simított értéket. Ha i = 2, akkor az átlagérték a számtani átlag lesz.
A kezdeti intervallum utolsó pontján a mozgóátlag sem számítható ki, mivel a számított értékhez képest nincs jövőbeli érték.
Exponenciális simítási módszer– a mozgóátlaggal ellentétben a jövőbeli trend rövid távú előrejelzésére használható egy időszakra előre. Éppen ezért a módszernek egyértelmű előnye van az előzőhöz képest.
A sorozat bármely pontján a simított értékek kiszámításának algoritmusa 3 értéken alapul: Yi megfigyelt értéke egy adott ponton, a sorozat előző pontjának számított simított értéke és néhány előre meghatározott simítási együttható, amelyek állandóak. az egész sorozatban.
Fi = α*Yi +(α-1)*Fi
Yi a sorozat végpontjának tényleges értéke.
A sorozat előző pontjának simított értéke - (alfa-1)
Az alfa bármilyen értéket felvehet 0 és 1 között, de a gyakorlatban általában a 0,2 és 0,5 közötti intervallumra korlátozódik.
Holt módszer. L t =k*Y t +(1-k)*(L t-1 -T t-1), ahol
L t az aktuális időszak simított értéke;
K a soros simítási együttható;
Y t a sorozat aktuális értéke (például értékesítési mennyiség);
L t-1 – simított érték az előző időszakra;
T t-1 – az előző időszak trendértéke.
Az előző három megjegyzés olyan regressziós modelleket írt le, amelyek a magyarázó változók értékei alapján jósolják meg a választ. Ebben a jegyzetben bemutatjuk, hogyan lehet ezeket a modelleket és más statisztikai módszereket használni az egymást követő időintervallumokban gyűjtött adatok elemzésére. A forgatókönyvben említett egyes vállalatok jellemzőinek megfelelően három alternatív megközelítést fogunk mérlegelni az idősorelemzéshez.
Az anyagot egy átvezető példával illusztráljuk: három cég bevétel-előrejelzése. Képzelje el, hogy Ön egy nagy pénzügyi vállalat elemzője. Ügyfelei befektetési kilátásainak felméréséhez három vállalat hozamát kell megjósolnia. Ennek érdekében három Önt érdeklő cégről gyűjtött adatokat – az Eastman Kodakról, a Cabot Corporationről és a Wal-Martról. Mivel a vállalatok üzleti tevékenységük típusában különböznek, minden idősornak megvannak a maga egyedi jellemzői. Ezért az előrejelzéshez különböző modelleket kell használni. Hogyan válasszuk ki a legjobb előrejelzési modellt az egyes vállalatok számára? Hogyan értékeljük a befektetési kilátásokat az előrejelzési eredmények alapján?
A megbeszélés az éves adatok elemzésével kezdődik. Az ilyen adatok simításának két módszerét mutatjuk be: a mozgóátlagot és az exponenciális simítást. Ezután bemutatja a trend kiszámításának eljárását a legkisebb négyzetek módszerével és a fejlettebb előrejelzési módszerekkel. Végül ezeket a modelleket kiterjesztik a havi vagy negyedéves adatokon alapuló idősorokra.
Jegyzet letöltése vagy formátumban, példák formátumban
Előrejelzés az üzleti életben
Mivel a gazdasági feltételek idővel változnak, a vezetőknek előre kell látniuk, hogy ezek a változások milyen hatással lesznek a vállalatukra. A pontos tervezés biztosításának egyik módja az előrejelzés. A kidolgozott módszerek nagy száma ellenére mindegyik ugyanazt a célt követi - a jövőben bekövetkező események előrejelzését, hogy ezeket figyelembe vegyék a vállalat fejlesztési terveinek és stratégiáinak kidolgozásakor.
A modern társadalom folyamatosan tapasztalja az előrejelzés szükségességét. Például a megfelelő politika érdekében a kormány tagjainak előre kell jelezniük a munkanélküliségi szintet, az inflációt, az ipari termelést, az egyének és a vállalatok jövedelemadóját. A felszerelési és személyzeti követelmények meghatározásához a légitársaságok igazgatóinak helyesen kell előre jelezniük a légi forgalom mennyiségét. Annak érdekében, hogy elegendő hely legyen a hostelben, a főiskolák vagy egyetemek adminisztrátorai tudni szeretnék, hány diák lép be jövőre intézményükbe.
Az előrejelzésnek két általánosan elfogadott megközelítése van: a kvalitatív és a mennyiségi. A kvalitatív előrejelzési módszerek különösen fontosak, ha a kvantitatív adatok nem állnak a kutató rendelkezésére. Általában ezek a módszerek erősen szubjektívek. Ha a vizsgált tárgy történetére vonatkozó adatok a statisztikus rendelkezésére állnak, kvantitatív előrejelzési módszereket kell alkalmazni. Ezek a módszerek lehetővé teszik egy objektum jövőbeli állapotának előrejelzését a múltjával kapcsolatos adatok alapján. A kvantitatív előrejelzési módszerek két kategóriába sorolhatók: idősorelemzés és ok-okozati elemzési módszerek.
idősorok egymást követő időszakokban nyert numerikus adatok halmaza. Az idősorelemzési módszer lehetővé teszi egy numerikus változó értékének előrejelzését a múltbeli és jelenbeli értékei alapján. Például a New York-i tőzsdén a napi részvényárak idősort alkotnak. Egy másik példa az idősorokra a havi fogyasztói árindex, a negyedéves bruttó hazai termék és a vállalat éves árbevétele.
Ok-okozati elemzési módszerek lehetővé teszi annak meghatározását, hogy milyen tényezők befolyásolják az előrejelzett változó értékeit. Ide tartoznak a többszörös regressziós elemzési módszerek késleltetett változókkal, az ökonometriai modellezés, a vezető mutatók elemzése, a diffúziós indexek és egyéb gazdasági mutatók elemzési módszerei. Csak az időelemzésen alapuló előrejelzési módszerekről lesz szó. s x sor.
A klasszikus multiplikatív időmodell összetevői s x sor
Az idősorok elemzésének alapjául szolgáló fő feltevés a következő: azok a tényezők, amelyek a jelenben és a múltban hatnak a vizsgált objektumra, hatással lesznek rá a jövőben is. Az idősorelemzés fő céljai tehát az előrejelzés szempontjából fontos tényezők azonosítása és kiemelése. E cél elérése érdekében számos matematikai modellt fejlesztettek ki az idősor-modellben szereplő komponensek ingadozásának vizsgálatára. Valószínűleg a legelterjedtebb az éves, negyedéves és havi adatok klasszikus multiplikatív modellje. A klasszikus multiplikatív idősor-modell bemutatásához vegye figyelembe a Wm.Wrigley Jr. cég tényleges bevételére vonatkozó adatokat. Vállalat az 1982 és 2001 közötti időszakra (1. ábra).
Rizs. 1. Wm.Wrigley Jr. tényleges bruttó bevételének grafikonja. Vállalat (folyó áron millió dollár) az 1982 és 2001 közötti időszakra
Mint látható, 20 év alatt a vállalat tényleges bruttó bevétele növekvő tendenciát mutatott. Ezt a hosszú távú trendet trendnek nevezzük. irányzat nem az egyetlen összetevője az idősornak. Ezen kívül az adatok ciklikus és szabálytalan összetevőket tartalmaznak. Ciklikus összetevő az adatok felfelé és lefelé történő ingadozását írja le, gyakran összefüggésben az üzleti ciklusokkal. Hossza 2 és 10 év között változik. A ciklikus komponens intenzitása vagy amplitúdója szintén nem állandó. Egyes években az adatok magasabbak lehetnek a trend által előre jelzett értéknél (azaz a ciklus csúcsa közelében), más években alacsonyabbak lehetnek (azaz a ciklus alján). Minden olyan megfigyelt adatot, amely nem fekszik trendgörbén, és nem áll ciklikus összefüggésben, szabálytalannak, ill. véletlenszerű komponensek. Ha naponta vagy negyedévente rögzítik az adatokat, akkor van egy további komponens, az úgynevezett szezonális. ábrán látható a gazdasági alkalmazásokra jellemző idősor összes komponense. 2.
Rizs. 2. Az idősort befolyásoló tényezők
A klasszikus multiplikatív idősor-modell szerint bármely megfigyelt érték a felsorolt komponensek szorzata. Ha az adatok évesek, a megfigyelés Yén megfelelő énévet a következő egyenlettel fejezzük ki:
(1) Y i = T i* C i* én i
ahol T i- trendérték, C i énév, én i én-adik év.
Ha az adatok mérése havonta vagy negyedévente történik, megfigyelés Y i, amely az i-edik periódusnak felel meg, a következő egyenlettel fejeződik ki:
(2) Y i = T i *S i *C i *I i
ahol T i- trendérték, Si- a szezonális komponens értéke ben én-adik időszak, C i- a ciklikus komponens értéke in én-adik időszak, én i- a véletlen komponens értéke in én-adik időszak.
Az idősorelemzés első szakaszában az adatok grafikonját ábrázolják, és feltárják az időtől való függésüket. Először azt kell kideríteni, hogy van-e hosszú távú növekedés vagy csökkenés az adatokban (azaz trend), vagy az idősor egy vízszintes vonal körül ingadozik. Ha nincs trend, akkor mozgóátlagok vagy exponenciális simítás használható az adatok simítására.
Simító éves idősorozat
A forgatókönyvben megemlítettük a Cabot Corporationt. Székhelye Bostonban, Massachusettsben található, és vegyi anyagok, építőanyagok, finom vegyszerek, félvezetők és cseppfolyósított földgáz gyártására és értékesítésére specializálódott. A cégnek 39 gyára van 23 országban. A cég piaci értéke mintegy 1,87 milliárd dollár, részvényeit a New York-i tőzsdén CBT rövidítéssel jegyzik. A társaság meghatározott időszakra vonatkozó bevételeit a 2. ábra mutatja. 3.

Rizs. 3. A Cabot Corporation bevétele 1982-2001 között (milliárd dollár)
Mint látható, a jövedelmek hosszú távú emelkedő trendjét számos ingadozás eltakarja. Így a grafikon vizuális elemzése nem teszi lehetővé, hogy kijelentsük, hogy az adatoknak van trendje. Ilyen helyzetekben alkalmazhatja a mozgóátlagos vagy az exponenciális simítás módszereit.
Mozgóátlagok. A mozgóátlag módszer nagyon szubjektív, és az időszak hosszától függ. L az átlagok kiszámításához választották ki. A ciklikus ingadozások kiküszöbölése érdekében a periódus hosszának az átlagos ciklushossz egész számú többszörösének kell lennie. Mozgóátlagok a kiválasztott időszakra, amelynek van hossza L, hosszúságú sorozatokra számított átlagértékek sorozatát alkotják L. A mozgóátlagokat szimbolizálják MA(L).
Tegyük fel, hogy ötéves mozgóátlagokat akarunk kiszámítani a mért adatokból n= 11 év. Amennyiben L= 5, az ötéves mozgóátlagok az idősor öt egymást követő értékére számított átlagok sorozatát alkotják. Az ötéves mozgóátlagok közül az elsőt úgy számítják ki, hogy az első öt év adatait összeadják, majd elosztják öttel:
![]()
A második ötéves mozgóátlagot úgy számítjuk ki, hogy a 2–6. évek adatait összeadjuk, majd elosztjuk öttel:
![]()
Ez a folyamat addig tart, amíg az elmúlt öt év mozgóátlagát ki nem számítják. Az éves adatokkal való munka során a számot kell feltételezni L(a mozgóátlagok kiszámításához kiválasztott időszak hossza) páratlan. Ebben az esetben nem lehet mozgóátlagokat számítani az első ( L– 1)/2 és utolsó ( L– 1)/2 év. Ezért az ötéves mozgóátlagokkal végzett munka során nem lehet számításokat végezni az első két és az utolsó két évre vonatkozóan. Az év, amelyre a mozgóátlagot számítják, egy hosszú időszak közepén kell, hogy legyen L. Ha n= 11, a L= 5, az első mozgóátlagnak meg kell felelnie a harmadik évnek, a másodiknak a negyediknek, az utolsónak pedig a kilencediknek. ábrán A 4. ábra 3 és 7 éves mozgóátlag diagramokat mutat be a Cabot Corporation 1982 és 2001 közötti bevételeire vonatkozóan.

Rizs. 4. Grafikonok a Cabot Corporation bevételére számított 3 és 7 éves mozgóátlagokról
Vegye figyelembe, hogy az első és az utolsó évnek megfelelő megfigyelt értékeket figyelmen kívül hagyjuk a hároméves mozgóátlagok kiszámításakor. Hasonlóképpen, a hétéves mozgóátlagok kiszámításakor az első és az utolsó három évre vonatkozóan nincs eredmény. Ráadásul a hétéves mozgóátlagok sokkal jobban kisimítják az idősorokat, mint a hároméves mozgóátlagok. Ennek az az oka, hogy a hétéves mozgóátlagok hosszabb időszaknak felelnek meg. Sajnos minél hosszabb az időszak, annál kevesebb mozgóátlag számítható ki és jeleníthető meg a diagramon. Ezért nem kívánatos hét évnél hosszabb időt választani a mozgóátlagok kiszámításához, mivel túl sok pont esik ki a diagram elejéről és végéről, ami torzítja az idősor alakját.
Exponenciális simítás. Az adatok változását jellemző hosszú távú trendek azonosítására a mozgóátlagok mellett az exponenciális simítási módszert alkalmazzuk. Ez a módszer lehetővé teszi rövid távú (egy perióduson belüli) előrejelzések készítését is, ha a hosszú távú trendek megléte kérdéses. Ennek köszönhetően az exponenciális simítási módszer jelentős előnnyel rendelkezik a mozgóátlagos módszerrel szemben.
Az exponenciális simítási módszer a nevét exponenciálisan súlyozott mozgóátlagok sorozatáról kapta. Ebben a sorozatban minden érték az összes korábbi megfigyelhető értéktől függ. Az exponenciális simítási módszer másik előnye a mozgóátlagos módszerrel szemben, hogy az utóbbi használatakor bizonyos értékeket el kell vetni. Az exponenciális simítással a megfigyelt értékekhez rendelt súlyok idővel csökkennek, így a számítások elvégzése után a leggyakrabban előforduló értékek kapnak a legnagyobb súlyt, a ritka értékek pedig a legkisebb súlyt. A rengeteg számítás ellenére az Excel lehetővé teszi az exponenciális simítási módszer megvalósítását.
Egy egyenlet, amely lehetővé teszi az idősorok tetszőleges időtartamon belüli simítását én, három tagot tartalmaz: az aktuális megfigyelt értéket Yén, idősorhoz tartozó, előző exponenciálisan simított érték Eén –1 és hozzárendelt súlyt W.
(3) E 1 = Y 1 E i = WY i + (1 – W) E i–1 , i = 2, 3, 4, …
ahol Eén-ra számított exponenciálisan simított sorozat értéke én-adik időszak, E i –1 az exponenciálisan simított sorozat értéke a én– 1. időszak, Y i az idősor megfigyelt értéke ben én-adik időszak, W a szubjektív súly vagy simítási tényező (0< W < 1).
A sorozat tagjaihoz rendelt simítási tényező vagy súly kiválasztása alapvetően fontos, mert közvetlenül befolyásolja az eredményt. Sajnos ez a választás némileg szubjektív. Ha a kutató egyszerűen ki akarja zárni az idősorból a nem kívánt ciklikus vagy véletlenszerű ingadozásokat, akkor kis értékeket kell választani. W(közel a nullához). Másrészt, ha az idősort előrejelzésre használjuk, akkor nagy súlyt kell választani W(közel az egységhez). Az első esetben az idősorok hosszú távú trendjei egyértelműen megmutatkoznak. A második esetben a rövid távú előrejelzés pontossága nő (5. ábra).

Rizs. 5 Exponenciálisan simított idősorok (W=0,50 és W=0,25) a Cabot Corporation 1982-2001 közötti bevételi adataihoz; lásd a számítási képleteket az Excel fájlban
A következőre kapott exponenciálisan simított érték én időintervallum, használható a ( én+1)-edik intervallum:
![]()
A Cabot Corporation 2002-es bevételének előrejelzése a súlynak megfelelő exponenciálisan simított idősor alapján W= 0,25, a 2001-re számított simított érték használható. ábrából Az 5. ábra azt mutatja, hogy ez a szám 1 651,0 millió dollár. Amikor a vállalat 2002-es eredményadatai elérhetővé válnak, a (3) egyenlet alkalmazható, és a 2003-as bevételi szint megjósolható a simított 2002-es eredmény segítségével:
Elemző csomag Az Excel egy kattintással képes exponenciális simítást ábrázolni. Menjen végig a menün Adat → Adatelemzésés válassza ki a lehetőséget Exponenciális simítás(6. ábra). A megnyílt ablakban Exponenciális simításállítsa be a paramétereket. Sajnos az eljárás csak egy simított sorozat építését teszi lehetővé, így ha "játszani" akarunk a paraméterrel W, ismételje meg az eljárást.

Rizs. 6. Exponenciális simítás ábrázolása az Analysis Pack segítségével
Legkisebb négyzetszámú trendek és előrejelzések
Az idősor komponensei közül leggyakrabban a trendet tanulmányozzuk. Ez az a trend, amely lehetővé teszi rövid és hosszú távú előrejelzések készítését. Egy idősor hosszú távú trendjének azonosításához általában egy grafikont ábrázolnak, amelyen a megfigyelt adatok (a függő változó értékei) a függőleges tengelyen, valamint az időintervallumok (a független változó értékei) vannak ábrázolva. a vízszintes tengelyen vannak ábrázolva. Ebben a részben a lineáris, másodfokú és exponenciális trend azonosításának eljárását ismertetjük a legkisebb négyzetek módszerével.
Lineáris trendmodell az előrejelzéshez használt legegyszerűbb modell: Y i = β 0 + β 1 X i + ε i . Lineáris trend egyenlet:
![]()
Adott α szignifikanciaszint esetén a nullhipotézist elvetjük, ha a tesztet t- a statisztikák nagyobbak, mint a felső vagy kisebbek az alsó kritikus szintnél t-elosztások. Vagyis a döntési szabály a következőképpen fogalmazódik meg: ha t > tU vagy t < t L, null hipotézist H 0 elutasításra kerül, ellenkező esetben a nullhipotézist nem utasítják el (14. ábra).

Rizs. 14. Hipotéziselvetési területek a kétoldali autoregressziós paraméter szignifikancia teszthez A r, amely a legmagasabb rendű
Ha a nullhipotézis ( A r= 0) nincs elutasítva, ami azt jelenti, hogy a kiválasztott modell túl sok paramétert tartalmaz. A kritérium lehetővé teszi, hogy elvesük a modell vezető tagját, és értékeljük az autoregresszív sorrendű modellt р–1. Ezt az eljárást a nullhipotézisig kell folytatni H 0 nem utasítják el.
Az autoregresszív modellezés bemutatásához térjünk vissza a Wm cég reáljövedelmének idősoros elemzéséhez. Wrigley Jr. ábrán A 15. ábra az első, másod- és harmadrendű autoregresszív modellek felépítéséhez szükséges adatokat mutatja. Harmadrendű modell felépítéséhez a táblázat összes oszlopára szükség van. Másodrendű autoregresszív modell felépítésekor az utolsó oszlop figyelmen kívül marad. Elsőrendű autoregresszív modell felépítésekor az utolsó két oszlop figyelmen kívül marad. Így az első, második és harmadrendű autoregresszív modellek megalkotásakor 20 változó közül egy, kettő és három változót zárunk ki.

A legpontosabb autoregresszív modell kiválasztása egy harmadrendű modellel kezdődik. A helyes működés érdekében Elemző csomag beviteli intervallumként következik Y adja meg a B5:B21 tartományt és a beviteli intervallumot x– C5:E21. Az elemzési adatok az ábrán láthatók. tizenhat.

Ellenőrizze a paraméter jelentőségét A 3, amely a legmagasabb rendű. A pontszáma egy 3értéke -0,006 (C20 cella a 16. ábrán), a standard hiba pedig 0,326 (D20 cella). A H 0: A 3 = 0 és H 1: A 3 ≠ 0 hipotézisek teszteléséhez kiszámítjuk t- statisztika:

t Az n–2p–1 = 20–2*3–1 = 13 szabadságfokú kritériumok: t L= DIÁK.INR(0,025; 13) = -2,160; t U\u003d STUDENT.INR (0,975, 13) \u003d +2,160. Mert -2,160< t = –0,019 < +2,160 и R= 0,985 > α = 0,05, nullhipotézis H 0 nem utasítható el. Így a harmadik rendű paraméternek nincs statisztikai jelentősége az autoregresszív modellben, ezért el kell távolítani.
Ismételjük meg a másodrendű autoregresszív modell elemzését (17. ábra). A legmagasabb rendű paraméter becslése, a 2= -0,205, standard hibája pedig 0,276. A H 0: A 2 = 0 és H 1: A 2 ≠ 0 hipotézisek teszteléséhez kiszámítjuk t- statisztika:


α = 0,05 szignifikanciaszinten a kétoldali kritikus értékei t Az n–2p–1 = 20–2*2–1 = 15 szabadságfokú kritériumok: t L\u003d STUDENT.OBR (0,025; 15) \u003d -2,131; t U\u003d STUDENT.OBR (0,975, 15) \u003d +2,131. Mert -2,131< t = –0,744 < –2,131 и R= 0,469 > α = 0,05, nullhipotézis H 0 nem utasítható el. Így a másodrendű paraméter statisztikailag nem szignifikáns, ezért el kell távolítani a modellből.
Ismételjük meg az elsőrendű autoregresszív modell elemzését (18. ábra). A legmagasabb rendű paraméter becslése, egy 1= 1,024, standard hibája pedig 0,039. A H 0: A 1 = 0 és H 1: A 1 ≠ 0 hipotézisek teszteléséhez kiszámítjuk t- statisztika:


α = 0,05 szignifikanciaszinten a kétoldali kritikus értékei t Az n–2p–1 = 20–2*1–1 = 17 szabadságfokú kritériumok: t L\u003d STUDENT.OBR (0,025; 17) \u003d -2,110; t U\u003d STUDENT.OBR (0,975, 17) \u003d +2,110. Mert -2,110< t = 26,393 < –2,110 и R = 0,000 < α = 0,05, нулевую гипотезу H 0 el kell utasítani. Így az elsőrendű paraméter statisztikailag szignifikáns, és nem szabad eltávolítani a modellből. Tehát az elsőrendű autoregresszív modell jobban közelíti az eredeti adatokat, mint mások. Becslések használata egy 0 = 18,261, egy 1= 1,024 és az utolsó évre vonatkozó idősor értéke - Y 20 = 1 371,88, megjósolhatjuk a vállalat Wm reáljövedelmének értékét. Wrigley Jr. Cégünk 2002-ben:
Megfelelő előrejelzési modell kiválasztása
A fentiekben hat módszert ismertettünk az idősorok értékeinek előrejelzésére: lineáris, másodfokú és exponenciális trendmodelleket, valamint autoregresszív első-, másod- és harmadrendű modelleket. Van optimális modell? A hat leírt modell közül melyiket kell használni egy idősor értékének előrejelzésére? Az alábbiakban felsorolunk négy alapelvet, amelyeknek vezérelniük kell a megfelelő előrejelzési modell kiválasztását. Ezek az elvek a modell pontosságára vonatkozó becsléseken alapulnak. Feltételezzük, hogy az idősor értékei megjósolhatók a korábbi értékek tanulmányozásával.
Az előrejelzési modellek kiválasztásának alapelvei:
Maradékelemzés. Emlékezzünk vissza, hogy a maradék az előrejelzett és a megfigyelt értékek különbsége. Miután felépített egy modellt egy idősorhoz, ki kell számítania a maradékokat mindegyikre n időközönként. ábrán látható módon. 19. ábra, A panel, ha a modell megfelelő, a maradékok az idősor véletlenszerű összetevői, ezért szabálytalan eloszlásúak. Másrészt, ahogy a többi panelen is látható, ha a modell nem megfelelő, a reziduumok szisztematikus függőséggel rendelkezhetnek, amely nem veszi figyelembe sem a trendet (B panel), sem a ciklikusságot (C panel), vagy a szezonális komponens (D panel).

Rizs. 19. Maradékelemzés
Abszolút és négyzetes középhibák mérése. Ha a reziduumok elemzése nem teszi lehetővé az egyetlen megfelelő modell meghatározását, akkor a maradék hiba nagyságának becslésén alapuló egyéb módszerek is alkalmazhatók. Sajnos a statisztikusok nem jutottak konszenzusra az előrejelzéshez használt modellek maradék hibáinak legjobb becslését illetően. A legkisebb négyzetek elve alapján először végezhet regressziós elemzést, és számíthatja ki a becslés standard hibáját SXY. Egy adott modell elemzésekor ez az érték az idősor tényleges és előrejelzett értékei közötti különbség négyzetének összege. Ha a modell tökéletesen közelíti az idősorok értékeit az előző időpontokban, akkor a becslés standard hibája nulla. Másrészt, ha a modell nem közelíti jól az idősorok korábbi időpontokban mért értékeit, akkor a becslés standard hibája nagy. Így több modell megfelelőségét elemezve választhatunk olyan modellt, amelynek az S XY becslés minimális standard hibája van.
Ennek a megközelítésnek a fő hátránya az, hogy túlzásba viszi a hibákat az egyes értékek előrejelzésében. Más szóval, bármilyen nagy eltérés az értékek között Yénés Ŷ én a négyzetes hibák összegének számításakor az SSE négyzetes, azaz. növeli. Emiatt sok statisztikus inkább az átlagos abszolút eltérést (MAD) használja az előrejelzési modell megfelelőségének értékelésére:

Konkrét modellek elemzésekor a MAD érték az idősor tényleges és előrejelzett értékei közötti különbségek moduljainak átlagértéke. Ha a modell tökéletesen közelíti az idősorok értékeit az előző időpontokban, akkor az átlagos abszolút eltérés nulla. Másrészt, ha a modell nem illeszkedik jól az ilyen idősor értékekhez, akkor az átlagos abszolút eltérés nagy. Így több modell megfelelőségét elemezve ki lehet választani azt a modellt, amelynél a legkisebb az átlagos abszolút eltérés.
A gazdaságosság elve. Ha a becslések standard hibáinak és az átlagos abszolút eltéréseknek az elemzése nem teszi lehetővé az optimális modell meghatározását, akkor egy negyedik, a takarékosság elvén alapuló módszer alkalmazható. Ez az elv kimondja, hogy több egyenlő modell közül a legegyszerűbbet kell választani.
A fejezetben tárgyalt hat előrejelzési modell közül a legegyszerűbbek a lineáris és kvadratikus regressziós modellek, valamint az elsőrendű autoregresszív modell. A többi modell sokkal összetettebb.
Négy előrejelzési módszer összehasonlítása. Az optimális modell kiválasztásának folyamatának szemléltetésére térjünk vissza a vállalat Wm reáljövedelmének értékeit tartalmazó idősorokhoz. Wrigley Jr. vállalat. Hasonlítsunk össze négy modellt: lineáris, másodfokú, exponenciális és autoregresszív elsőrendű modellt. (A másod- és harmadrendű autoregresszív modellek csak kis mértékben javítják az adott idősor értékeinek előrejelzésének pontosságát, így figyelmen kívül hagyhatók.) A 20. ábra négy predikciós módszer elemzése során felépített reziduumok diagramjait mutatja be Elemző csomag Excel. A grafikonok alapján történő következtetések levonásakor óvatosnak kell lenni, mivel az idősor mindössze 20 pontot tartalmaz. Az építési módszereket lásd az Excel fájl megfelelő lapján.

Rizs. 20. Négy előrejelzési módszer elemzése során megszerkesztett reziduumok diagramja Elemző csomag excel
Az elsőrendű autoregresszív modellen kívül egyetlen modell sem veszi figyelembe a ciklikus komponenst. Ez a modell az, amely jobban közelíti a megfigyeléseket, mint mások, és a legkevésbé szisztematikus szerkezet jellemzi. Tehát mind a négy módszer reziduumainak elemzése azt mutatta, hogy a legjobb az elsőrendű autoregresszív modell, a lineáris, másodfokú és exponenciális modellek pedig kisebb pontosságúak. Ennek ellenőrzésére hasonlítsuk össze ezen módszerek maradék hibáit (21. ábra). A számítási módszer az Excel fájl megnyitásával érhető el. ábrán 21 a tényleges értékek Y i(hangszóró Valós bevétel), előrejelzett értékek Ŷ én, valamint a maradék eén mind a négy modellhez. Ezenkívül az értékek megjelennek SYXés ŐRÜLT.. Mind a négy mennyiségi modellhez s SYXés ŐRÜLT. nagyjából ugyanaz. Az exponenciális modell viszonylag gyengébb, míg a lineáris és a kvadratikus modellek pontosabbak. Ahogy az várható volt, a legkisebb értékek SYXés ŐRÜLT. elsőrendű autoregresszív modellje van.

Rizs. 21. Négy előrejelzési módszer összehasonlítása S YX és MAD mutatókkal
A konkrét előrejelzési modell kiválasztása után az idősorok további változásait gondosan figyelemmel kell kísérni. Többek között egy ilyen modellt hoznak létre annak érdekében, hogy a jövőben helyesen megjósolják az idősorok értékeit. Sajnos az ilyen előrejelzési modellek nem veszik figyelembe az idősorok szerkezetében bekövetkezett változásokat. Feltétlenül össze kell hasonlítani nemcsak a maradék hibát, hanem a más modellekkel kapott idősorok jövőbeli értékeinek előrejelzésének pontosságát is. Az új érték mérésével Yén a megfigyelt időintervallumban azonnal össze kell hasonlítani az előrejelzett értékkel. Ha a különbség túl nagy, az előrejelzési modellt felül kell vizsgálni.
Idő-előrejelzés s x sorozat szezonális adatok alapján
Eddig éves adatokból álló idősorokat vizsgáltunk. Sok idősor azonban negyedévente, havonta, hetente, naponta, sőt óránként mért mennyiségekből áll. ábrán látható módon. 2, ha az adatokat havonta vagy negyedévente mérik, akkor a szezonális összetevőt kell figyelembe venni. Ebben a részben megvizsgáljuk az ilyen idősorok értékeinek előrejelzésére szolgáló módszereket.
A fejezet elején leírt forgatókönyvben a Wal-Mart Stores, Inc. szerepelt. A cég piaci kapitalizációja 229 milliárd dollár, részvényeit a New York-i tőzsdén WMT rövidítéssel jegyzik. A társaság pénzügyi éve január 31-én zárul, így 2002 negyedik negyedéve 2001 novemberét és decemberét, valamint 2002 januárját tartalmazza. ábra mutatja a társaság negyedéves eredményének idősorát. 22.

Rizs. 22. Wal-Mart Stores, Inc. negyedéves eredménye. (millió dollár)
Az ilyen negyedéves sorozatoknál, mint a mostani, a klasszikus multiplikatív modell a trend, ciklikus és véletlenszerű komponensen kívül szezonális komponenst is tartalmaz: Y i = T i* Si* C i* én i
A havi és ideiglenes előrejelzés s x sor a legkisebb négyzetek módszerével. A szezonális komponenst tartalmazó regressziós modell kombinált megközelítésen alapul. A trend kiszámításához a korábban ismertetett legkisebb négyzetek módszerét, a szezonális komponenst pedig egy kategorikus változóval (további részletekért lásd a Dummy változós regressziós modellek és interakciós hatások). Exponenciális modellt használunk az idősorok közelítésére a szezonális összetevők figyelembevételével. A negyedéves idősorokat közelítő modellben három álváltozóra volt szükségünk a négy negyedév elszámolásához Q1, Q2és Q 3, és a havi idősor modelljében 12 hónapot 11 álváltozóval ábrázolunk. Mivel ezek a modellek a log változót használják válaszként Y i, de nem Y i, a valós regressziós együtthatók kiszámításához inverz transzformációt kell végrehajtani.
A negyedéves idősorokat megközelítő modell felépítésének folyamatának illusztrálására térjünk vissza a Wal-Mart bevételeihez. A segítségével kapott exponenciális modellparaméterek Elemző csomagábrán látható az Excel. 23.

Rizs. 23. A Wal-Mart Stores, Inc. negyedéves bevételeinek regressziós elemzése.
Látható, hogy az exponenciális modell elég jól közelíti az eredeti adatokat. Vegyes korrelációs együttható r 2 egyenlő 99,4%-kal (J5 cellák), korrigált vegyes korrelációs együttható - 99,3% (J6 cellák), teszt F-statisztika - 1333,51 (M12 cellák), ill R-értéke 0.0000. α = 0,05 szignifikanciaszinten a klasszikus multiplikatív idősor modellben minden regressziós együttható statisztikailag szignifikáns. A potenciálási műveletet alkalmazva rájuk a következő paramétereket kapjuk:

Esély ![]() a következőképpen értelmezzük.
a következőképpen értelmezzük.
Regressziós együtthatók használata b i, megjósolhatja, hogy egy vállalat mekkora bevételt termel egy adott negyedévben. Például jósoljuk meg egy vállalat bevételét 2002 negyedik negyedévére ( xén = 35):
log= b 0 + b 1 xén = 4,265 + 0,016*35 = 4,825
= 10 4,825 = 66 834
Így a 2002. negyedik negyedévi előrejelzés szerint a cégnek 67 milliárd dollár bevételre kellett volna szert tennie (aligha kell milliós pontosságú előrejelzést készíteni). Az előrejelzés kiterjesztése az idősoron kívüli időszakra, például 2003 első negyedévére ( xén = 36, Q1= 1), a következő számításokat kell elvégezni:
log Ŷi = b 0 + b 1xén + b 2 Q 1 = 4,265 + 0,016*36 – 0,093*1 = 4,748
10 4,748 = 55 976
Indexek
Az indexeket olyan mutatókként használják, amelyek reagálnak a gazdasági helyzet vagy az üzleti tevékenység változásaira. Az indexeknek számos fajtája létezik, különösen az árindexek, a mennyiségi indexek, az értékindexek és a szociológiai indexek. Ebben a részben csak az árindexet vesszük figyelembe. Index- valamely gazdasági mutató (vagy mutatócsoport) értéke egy adott időpontban, a bázisidőponti értékének százalékában kifejezve.
Árindex. Az egyszerű árindex egy áru (vagy árucsoport) árának egy adott időszak alatti százalékos változását tükrözi az adott áru (vagy árucsoport) árához képest a múlt egy adott időpontjában. Az árindex kiszámításakor mindenekelőtt egy alapidőintervallumot kell választani - egy olyan múltbeli időintervallumot, amellyel az összehasonlítást végezzük. Egy adott index bázisidőszakának kiválasztásakor a gazdasági stabilitás időszakait részesítik előnyben a gazdasági expanzió vagy recesszió időszakaival szemben. Emellett a bázisidőszak ne legyen túlságosan távoli időben, hogy az összehasonlítás eredményét ne befolyásolják túl erősen a technológiai és fogyasztói szokások változásai. Az árindex kiszámítása a következő képlettel történik:

ahol én i- árindex be énév, Rén- ár be énév, P alapok- bázisévi ár.
Árindex - egy termék (vagy termékcsoport) árának egy adott időszakon belüli százalékos változása a termék árához viszonyítva egy bázisidőpontban. Példaként vegyük az ólommentes benzin árindexét az Egyesült Államokban 1980 és 2002 között (24. ábra). Például:


Rizs. 24. Ólommentes benzin gallononkénti ára és amerikai egyszerű árindex 1980 és 2002 között (bázisév 1980 és 1995)
Így 2002-ben az ólommentes benzin ára az USA-ban 4,8%-kal volt magasabb, mint 1980-ban. 24. ábra mutatja, hogy az árindex 1981-ben és 1982-ben 1980-ban az árindex felett volt, majd 2000-ig nem haladta meg az alapszintet. Mivel 1980-at választották bázisidőszaknak, valószínűleg érdemes közelebbi évet választani, például 1995-öt. Az index új bázisidőszakhoz viszonyított újraszámításának képlete a következő:

ahol énúj- új árindex, énrégi- régi árindex, énúj bázis - az árindex értéke az új bázisévben a régi bázisévre számítva.
Tegyük fel, hogy 1995-öt választották új alapnak. A (10) képlet segítségével új árindexet kapunk 2002-re:
Így 2002-ben az ólommentes benzin az Egyesült Államokban 13,9%-kal többe került, mint 1995-ben.
Súlyozatlan összetett árindexek. Bár minden egyes termék árindexe kétségtelenül érdekes, egy árucsoport árindexe sokkal fontosabb, amely lehetővé teszi nagyszámú fogyasztó költségének és életszínvonalának felmérését. A (11) képlettel meghatározott súlyozatlan összetett árindex ugyanazt a súlyt rendeli minden egyes árutípushoz. Az összetett árindex egy árucsoport (gyakran fogyasztói kosárnak nevezik) árának százalékos változását tükrözi egy adott időszakban az adott árucsoport bázisidőponti árához viszonyítva.

ahol t én- cikkszám (1, 2, …, n), n- a szóban forgó csoportban lévő áruk száma, - az egyes áruk árának összege nárut egy adott időszakban t, az egyes árak összege náruk a nulla periódusban, - a súlyozatlan összetett index értéke az időszakban t.
ábrán A 25. ábra háromféle gyümölcs átlagárait mutatja be az 1980-tól 1999-ig tartó időszakra vonatkozóan. A súlyozatlan összetett árindex különböző években történő kiszámításához a (11) képletet használjuk, figyelembe véve az 1980-as bázisévet.
Tehát 1999-ben egy font alma, egy font banán és egy font narancs összára 59,4%-kal volt magasabb, mint ezeknek a gyümölcsöknek az ára 1980-ban.

Rizs. 25. Három gyümölcs ára (dollárban) és egy súlyozatlan összetett árindex
A súlyozatlan összetett árindex egy teljes árucsoport árváltozását fejezi ki az idő múlásával. Bár ez az index könnyen kiszámítható, két külön hátránya van. Először is, ennek az indexnek a kiszámításakor minden típusú árut egyformán fontosnak tekintünk, így a drága áruk szükségtelen befolyást gyakorolnak az indexre. Másodszor, nem minden árut fogyasztanak egyforma mértékben, így a keveset fogyasztott áruk árának változása túlságosan befolyásolja a súlyozatlan indexet.
Súlyozott összetett árindexek. A súlyozatlan árindexek hátrányai miatt a súlyozott árindexeket részesítik előnyben, figyelembe véve a fogyasztói kosarat alkotó áruk ár- és fogyasztási szintjeit. Kétféle súlyozott összetett árindex létezik. Lapeyre árindex, amelyet a (12) képlet határoz meg, a bázisévi fogyasztási szinteket használja. A súlyozott összetett árindex figyelembe veszi a fogyasztói kosarat alkotó áruk fogyasztási szintjeit, és minden termékhez egy bizonyos súlyt rendel.

ahol t- időszak (0, 1, 2, ...), én- cikkszám (1, 2, …, n), n én a nulla periódusban, - a Lapeyre index értéke az időtartamban t.
A Lapeyre-index számításait az 1. ábra mutatja. 26; Az 1980-as év a bázisév.

Rizs. 26. A háromféle gyümölcs ára (dollárban), mennyisége (fogyasztás fontban/fő) és a Lapeyre-index
Tehát a Lapeyre-index 1999-ben 154,2. Ez azt jelzi, hogy 1999-ben ez a háromféle gyümölcs 54,2%-kal volt drágább, mint 1980-ban. Vegye figyelembe, hogy ez az index kisebb, mint a súlyozatlan 159,4-es index, mivel a narancs, a legkevésbé fogyasztott gyümölcs többet emelkedett, mint az alma és a banán. Más szóval, mivel a legtöbbet fogyasztott gyümölcsök ára kevésbé emelkedett, mint a narancsé, a Lapeyret index kisebb, mint a súlyozatlan összetett index.
Paasche árindex a termék fogyasztási szintjeit az aktuális időszakban használja, nem a bázisidőszakban. Ezért a Paasche-index pontosabban tükrözi az áruk elfogyasztásának teljes költségét egy adott időpontban. Ennek az indexnek azonban két jelentős hátránya van. Először is, a jelenlegi fogyasztási szintet általában nehéz meghatározni. Emiatt sok népszerű index a Lapeyret indexet használja a Paasche index helyett. Másodszor, ha egy adott áru ára a fogyasztói kosárban meredeken megemelkedik, a fogyasztók kényszerűségből csökkentik fogyasztásukat, nem az ízek megváltozása miatt. A Paasche-index kiszámítása a következő képlettel történik:

ahol t- időszak (0, 1, 2, ...), én- cikkszám (1, 2, …, n), n- a vizsgált csoportba tartozó áruk száma, - az áruk darabszáma én a nulla periódusban, - a Paasche index értéke az időtartamban t.
A Paasche-index számításait az 1. ábra mutatja. 27; Az 1980-as év a bázisév.

Rizs. 27. A háromféle gyümölcs ára (dollárban), mennyisége (fogyasztás fontban/fő) és a Paasche-index
Tehát a Paasche-index 1999-ben 147,0. Ez azt jelzi, hogy 1999-ben ez a háromféle gyümölcs 47,0%-kal volt drágább, mint 1980-ban.
Néhány népszerű árindex. Számos árindexet használnak az üzleti életben és a gazdaságban. A legnépszerűbb a fogyasztói árindex (CPI). Hivatalosan ezt az indexet CPI-U-nak hívják, hogy hangsúlyozzák, hogy városokra (városira) számítják, bár általában egyszerűen CPI-nek hívják. Ezt az indexet havonta közzéteszi az Egyesült Államok Munkaügyi Statisztikai Hivatala, amely az Egyesült Államok megélhetési költségeinek mérésének elsődleges eszköze. A fogyasztói árindex összetett és Lapeyre-súlyozású. Kiszámítása a 400 legszélesebb körben fogyasztott termék, a ruházati cikk, a szállítás, az egészségügy és a közüzemi szolgáltatások árából történik. A mutató számításánál jelenleg az 1982–1984 közötti időszakot veszik alapul. (28. ábra). A CPI-index fontos funkciója deflátorként való használata. A CPI-indexet a tényleges árak valós árakra való konvertálására használják úgy, hogy minden egyes árat megszoroznak 100/CPI-vel. A számítások azt mutatják, hogy az elmúlt 30 évben az Egyesült Államok átlagos éves inflációja 2,9% volt.

Rizs. 28. A fogyasztói indexár dinamikája; teljes adatot lásd excel fájlban
A Munkaügyi Statisztikai Hivatal által közzétett másik fontos árindex a termelői árindex (PPI). A PPI index egy súlyozott összetett index, amely a Lapeyret-módszert használja a gyártók által értékesített áruk árváltozásának becslésére. A PPI index a CPI index vezető mutatója. Más szóval, a PPI-index növekedése a CPI-index növekedéséhez vezet, és fordítva, a PPI-index csökkenése a CPI-index csökkenéséhez vezet. Az amerikai részvények értékében bekövetkezett változások mérésére olyan pénzügyi indexeket használnak, mint a Dow Jones Industrial Average (DJIA), az S&P 500 és a NASDAQ. Számos index lehetővé teszi a nemzetközi részvénypiacok jövedelmezőségének felmérését. Ezek az indexek közé tartozik a Nikkei Japánban, a Dax 30 Németországban és az SSE Composite Kínában.
Az időelemzéssel kapcsolatos buktatók s x sor
Egy olyan módszer jelentőségét, amely a múltra és a jelenre vonatkozó információkat használ fel a jövő megjóslására, Patrick Henry államférfi több mint kétszáz évvel ezelőtt ékesszólóan leírta: „Csak egy lámpám van, ami megvilágítja az utat – az én tapasztalatom. Csak a múlt ismerete teszi lehetővé a jövő megítélését.
Az idősorelemzés azon a feltételezésen alapul, hogy azok a tényezők, amelyek a múltban befolyásolták az üzleti tevékenységet és a jelent, a jövőben is működni fognak. Ha igaz, az idősorelemzés hatékony előrejelző és menedzsment eszköz. Az idősorelemzésen alapuló klasszikus módszerek kritikusai azonban azzal érvelnek, hogy ezek a módszerek túlságosan naivak és primitívek. Más szóval, a múltban működő tényezőket figyelembe vevő matematikai modellnek nem szabad mechanikusan extrapolálnia a trendeket a jövőre anélkül, hogy figyelembe venné a szakértői megítélést, az üzleti tapasztalatokat, a technológiai változásokat, valamint az emberek szokásait és igényeit. Ennek a helyzetnek a korrigálása érdekében az ökonometrikusok az elmúlt években a gazdasági tevékenység összetett számítógépes modelljeit dolgozták ki, amelyek figyelembe veszik a fent felsorolt tényezőket.
Az idősorelemzési módszerek azonban kiváló (rövid és hosszú távú) előrejelzési eszközt jelentenek, ha helyesen alkalmazzák, más előrejelzési módszerekkel kombinálva, figyelembe véve a szakértői megítélést és tapasztalatokat.
Összegzés. A jegyzetben idősorelemzés segítségével modelleket dolgoztak ki három vállalat bevételének előrejelzésére: Wm. Wrigley Jr. Társaság, a Cabot Corporation és a Wal-Mart. Leírjuk az idősorok összetevőit, valamint az éves idősorok előrejelzésének számos megközelítését - a mozgóátlagos módszert, az exponenciális simítási módszert, a lineáris, másodfokú és exponenciális modelleket, valamint az autoregresszív modellt. A szezonális komponensnek megfelelő dummy változókat tartalmazó regressziós modellt veszünk figyelembe. A legkisebb négyzetek módszerének alkalmazása a havi és negyedéves idősorok előrejelzésére látható (29. ábra).
P szabadságfokok elvesznek az idősorok értékeinek összehasonlításakor.
Az idősorelemzés lehetővé teszi a mutatók időbeli tanulmányozását. Az idősor egy statisztikai mutató számértékei időrendi sorrendben.
Az ilyen adatok általánosak az emberi tevékenység különböző területein: napi részvényárfolyamok, árfolyamok, negyedéves, éves eladások, termelés stb. Tipikus idősor a meteorológiában, például a havi csapadék.
Ha bizonyos időközönként rögzíti valamelyik folyamat értékeit, akkor megkapja az idősor elemeit. Változékonyságukat szabályos és véletlenszerű összetevőkre próbálják felosztani. A sorozat tagjainak rendszeres változásai általában előre láthatóak.
Végezzünk idősor elemzést Excelben. Példa: Egy kiskereskedelmi lánc elemzi az 50 000 főnél kisebb lélekszámú városokban található üzletek értékesítési adatait. Időszak - 2012-2015 A feladat a fő fejlesztési irányzat azonosítása.
Írjuk be az implementáció adatait az Excel táblázatba:
Az Adatok lapon kattintson az Adatelemzés gombra. Ha nem látható, lépjen a menübe. "Excel-beállítások" - "Bővítmények". Alul kattintson az "Ugrás" gombra az "Excel-bővítmények" elemre, és válassza az "Analysis Toolkit" lehetőséget.
Az „Adatelemzés” beállítás csatlakoztatását részletesen ismertetjük.
A kívánt gomb megjelenik a szalagon.

A statisztikai elemzéshez javasolt eszközök listájából válassza ki az „Exponenciális simítás” lehetőséget. Ez a kiegyenlítési módszer alkalmas idősorainkra, amelyek értékei erősen ingadoznak.
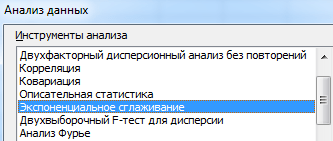
Töltse ki a párbeszédpanelt. A beviteli intervallum egy értékesítési értékeket tartalmazó tartomány. Csökkentési tényező – exponenciális simítási tényező (alapértelmezett – 0,3). Kimeneti tartomány – Hivatkozás a kimeneti tartomány bal felső cellájára. A program ide helyezi a simított szinteket, és önállóan határozza meg a méretet. Jelölje be a „Grafikon kimenet”, „Szabványos hibák” négyzetet.
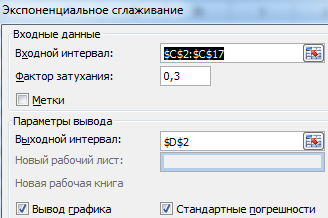
Zárja be a párbeszédpanelt az OK gombra kattintva. Elemzés eredménye:

A standard hibák kiszámításához az Excel a következő képletet használja: =SQRT(SUMQDIFF('valós értékek tartománya'; 'előrejelzett értékek tartománya')/'simítóablak mérete'). Például =ROOT(SUMDIFF(C3:C5,D3:D5)/3).
Készítsünk értékesítési előrejelzést az előző példa adatai alapján.
Adjunk hozzá egy trendvonalat a grafikonhoz, amely a termékértékesítés tényleges mennyiségét mutatja (a grafikon jobb gombja a "Trendvonal hozzáadása").
Állítsa be a trendvonal paramétereit:

Olyan polinomiális trendet választunk, amely a lehető legkisebbre csökkenti a prediktív modell hibáját.

R2 = 0,9567, ami azt jelenti, hogy ez az arány magyarázza az eladások időbeli változásának 95,67%-át.
A trendegyenlet egy képletmodell az előrejelzési értékek kiszámításához.
Meglehetősen optimista eredményt kapunk:

Példánkban végül is az exponenciális függés. Ezért a lineáris trend felépítésekor több a hiba és a pontatlanság.
A GROWTH függvényt exponenciális kapcsolat előrejelzésére is használhatja az Excelben.

Lineáris kapcsolathoz - TREND.
Előrejelzések készítésekor nem használhat egyetlen módszert sem: nagy a valószínűsége a nagy eltéréseknek és pontatlanságoknak.
2013.10.07. Tyler Chessman
Az idősoros előrejelzés kulcsfontosságú gondolatainak megértése és néhány részlet ismerete előnyt jelent az SQL Server Analysis Services (SSAS) előrejelzési képességeinek használatában.
Ez a cikk az adatbányászati technológiák elsajátításához szükséges alapfogalmakat ismerteti. Ezenkívül kitérünk néhány finomságra, hogy amikor a gyakorlatban találkozik velük, ne csüggedjen (lásd a "Miért olyan népszerűtlen az adatbányászat" című oldalsávot).
Az SQL Server szakembereinek időről időre előremutató becsléseket kell készíteniük a jövőbeli értékről, például a bevételről vagy az értékesítési előrejelzésekről. A szervezetek időnként adatbányászati technológiát alkalmaznak a prediktív modellek felépítéséhez, hogy ezeket a becsléseket biztosítsák. Miután megértette az alapfogalmakat és néhány részletet, elkezdi sikeresen használni az SQL Server Analysis Services (SSAS) előrejelzési képességeit.
Az előrejelzésnek többféle megközelítése létezik. Például a Forecasting Methods webhely (forecastingmethods.org) az előrejelzési módszerek különböző kategóriáit különbözteti meg, beleértve az alkalmi (más néven gazdasági-matematikai), szakértői modellezést (szubjektív), idősorokat, mesterséges intelligenciát, előrejelzési piacot, valószínűségi előrejelzést, előrejelzési modellezést, valamint a referenciaosztályokon alapuló metódus-előrejelzés. A Forecasting Principles webhely (www.forecastingprinciples.com) áttekintést nyújt a módszerekről egy módszertani fában, elsősorban a szubjektív módszereket (vagyis azokat a módszereket, amelyeket akkor használjuk, amikor nincs elegendő adat a számszerűsítéshez) és a statikus módszereket (azaz azokat a módszereket, amelyeket akkor használjuk, ha releváns számszerű adatok állnak rendelkezésre) elkülönítve egymástól. . Ebben a cikkben az idősoros előrejelzésre fogok összpontosítani, amely egy olyan statikus megközelítés, amelyben a felhalmozott adatok elegendőek a mutatók előrejelzéséhez.
Az idősoros előrejelzés azt feltételezi, hogy a múltban szerzett adatok segítenek megmagyarázni a jövőbeli értékeket. Fontos megérteni, hogy bizonyos esetekben olyan részletekkel van dolgunk, amelyek nem tükröződnek a felhalmozott adatokban. Például egy új versenytárs jelenik meg, amely hátrányosan befolyásolhatja a jövőbeni kereseteket, vagy a munkaerő összetételének gyors változásai, amelyek hatással lehetnek a munkanélküliségi rátára. Ilyen helyzetekben az idősoros előrejelzés nem lehet az egyetlen megközelítés. A legpontosabb előrejelzések érdekében gyakran különböző előrejelzési megközelítéseket kombinálnak.
Az idősorok egy bizonyos időszak alatt, általában rendszeres időközönként kapott értékek gyűjteménye. Gyakori példák a heti eladások, a negyedéves kiadások és a havi munkanélküliségi ráta. Az idősorok adatai grafikus formátumban jelennek meg, az időintervallum a diagram x tengelye mentén, az értékek pedig az y tengely mentén, amint az 1. ábrán látható.
Amikor megvizsgáljuk, hogyan változik egy érték az egyik periódusról a másikra, és hogyan lehet az értékeket megjósolni, szem előtt kell tartani, hogy az idősor adatoknak van néhány fontos jellemzője.
Tehát a trend azonosításával, a trendvonal átfedésével az alapvonalon, és az adatelemzésben esetleg jelen lévő szezonális komponens azonosításával egy prediktív modellt kap, amely felhasználható az értékek előrejelzésére:
Előrejelzett érték = kiindulási érték + trend + szezonális
Az alapérték és a trend meghatározásának egyetlen módja a regressziós módszer. A „regresszió” szó itt a változók közötti kapcsolat figyelembevételére utal. Ebben az esetben kapcsolat van a független időváltozó és a munkanélküliek számának függő változója között. Vegye figyelembe, hogy a független változót néha prediktornak is nevezik.
A regressziós módszer alkalmazásához használjon olyan eszközt, mint a Microsoft Excel. Például elvégezhet egy automatikus számítást Excelben, és trendvonalat adhat hozzá egy idősor diagramhoz a Diagrameszközök Elrendezés lap Trendvonal menüjének vagy az Excel 2010 vagy Excel 2007 panel Kimutatásdiagram Eszközök Elrendezés lapjának használatával. Az 1. ábrán I. egyenes trendvonalat adott a Trendline menü Mode Lineáris trendvonalának kiválasztásával. Ezután a Trendline menüben a További trendvonal-beállítások lehetőséget választottam, majd az Egyenlet megjelenítése a diagramon és az R-négyzet érték megjelenítése a diagramon opciókat, lásd a 3. ábrát.
.jpg) |
| 3. ábra: Trendbeállítások az Excelben |
Ezt a folyamatot, amely során a felhalmozott adatokhoz trendvonalat illesztünk, lineáris regressziónak nevezzük. Amint az 1. képernyőn láthatjuk, a trendvonal kiszámítása az egyenlet szerint történik, ahol az alapszintet (8248,8) és a trendet (104,67x) határozzuk meg:
y = 104,67x + 8248,8
A trendvonalat úgy képzelheti el, mint összekapcsolt x-y koordináták sorozatát, ahol beilleszthet egy időintervallumot (azaz x-tengelyt), hogy megkapjon egy értéket (y-tengely). Az Excel a „legjobb” trendvonalat a legkisebb négyzetek módszerével határozza meg (az 1. ábrán R²-ként definiálva). A legkisebb négyzetszámú vonal egy olyan vonal, amely minimalizálja a négyzetes függőleges távolságot a trendvonal minden pontjától a vonal megfelelő pontjáig. Az RMS értékek lehetővé teszik annak meghatározását, hogy a tényleges vonal feletti vagy alatti eltérések nem egyensúlyozzák ki egymást. Az 1. képernyőn azt látjuk, hogy R² = 0,5039, ami azt jelenti, hogy a lineáris összefüggés magyarázza a munkanélküliségi statisztikák időbeli változásának 50,39%-át.
A pontos trendvonal meghatározása az Excelben gyakran próba-hibával, valamint szemrevételezéssel jár. Az 1. képernyőn az egyenes trendvonal nem a legjobb illeszkedés. Az Excel további lehetőségeket kínál a trendvonalhoz, amelyet a 3. ábra lát. A 4. ábrához hozzáadtam egy négyperiódusos mozgóátlag vonalat, amely az idősor aktuális és utolsó beállított periódusának számtani átlagán alapul.
Ezenkívül hozzáadtam egy polinomiális trendvonalat egy algebrai egyenlet alkalmazásával a vonal ábrázolásához. Vegye figyelembe, hogy a polinomiális trendvonal R² értéke 0,9318, amely meghatározza a legjobb arányt a független és függő változók közötti kapcsolat kifejezésében. A magasabb R² azonban nem feltétlenül jelenti azt, hogy a trendvonal prediktív értéket ad. Vannak más módszerek is a pontos előrejelzések kiszámítására, amelyeket az alábbiakban röviden ismertetek. Az Excel egyes trendvonal-beállításai (például lineáris, polinomiális trendvonalak) lehetővé teszik előre és hátra előrejelzések készítését, figyelembe véve a periódusok számát, és a kapott értékeket grafikonon ábrázolják. Egyesek számára furcsának tűnhet az „előrejelzés ellenkező irányba” kifejezés. A legjobb ezt egy példával bemutatni. Tételezzük fel, hogy egy új tényező – a közszféra állásainak rohamos növekedése (pl. a honvédelmi állások a 2000-es évek elején, az Egyesült Államok Népszámlálási Hivatalának ideiglenes alkalmazottai) – a munkanélküliségi ráta gyors csökkenését idézte elő. Az új munkahelyek szektorának növekedési ütemét több hónapra visszafelé kell vetíteni, majd újra kell számolni a munkanélküliségi rátát, hogy simított változási ütemet kapjunk.
A trendvonal egyenletét manuálisan is alkalmazhatja a jövőbeli értékek kiszámításához. Az 5. ábrán polinomiális trendvonalat adtam hozzá egy 6 hónapos előrejelzéssel, először eltávolítva az utolsó 6 hónapot (vagyis 2012 áprilisától szeptemberig) az eredeti idősorból.
Ha összehasonlítja az 5. képernyőt az 1. képernyővel, láthatja, hogy a polinom előrejelzéseknek van egy emelkedő trendje, ami nincs összhangban a tényleges idősor csökkenő trendjével (trendjével).
A regresszióval kapcsolatban két fontos szempontot kell kiemelni.
A szezonális komponens az idősor szerkezetében általában vagy a hét napjával, vagy a hónap napjával, vagy az év hónapjával kapcsolatban jelenik meg. Amint fentebb megjegyeztük, a munkanélküliek száma az Egyesült Államokban jellemzően növekszik és csökken egy adott naptári évben. Ez akkor is igaz, ha a gazdaság növekszik, ahogy az a 2. ábrán látható. Vagyis a pontos előrejelzéshez figyelembe kell venni a szezonális összetevőt. Az egyik általános megközelítés a szezonálisan kiigazított módszer alkalmazása. A Practical Time Series Forecasting: A Hands-On Guide második kiadásában (CreateSpace Independent Publishing Platform, 2012) Galit Shmueli szerző a három módszer valamelyikének használatát javasolja:
Az alapszint és a trend meghatározása az előrejelzés számításánál történik, figyelembe véve a simított idősorokat. Opcionálisan szezonális komponens vagy korrekció újra alkalmazható az előrejelzési értékekre, figyelembe véve a szezonális tényező kezdeti értékeit a Holt-Winters módszerrel végzett munka során. Ha látni szeretné, hogyan készülnek a szezonális faktorszámítások az Excelben, írja be a „Winters metódus az Excelben” kifejezést az internetes keresősávba. A Holt-Winters módszer részletesebb magyarázatát lásd: Wayne L. Winston Microsoft Office Excel 2007: Data Analysis and Business Modeling, Second Edition (Microsoft Press, 2007).
Számos adatbányászati csomagban, például az SSAS-ban, az idősoros előrejelzési algoritmusok automatikusan figyelembe veszik a szezonális ingadozásokat azáltal, hogy mérik a szezonális kapcsolatokat, és beépítik azokat az előrejelzési modellbe. Érdemes azonban tippeket telepíteni a szezonális változások szerkezetére vonatkozóan.
Mint már említettük, az eredeti modell (ha a legkisebb négyzetek módszerét alkalmazzuk) nem feltétlenül biztosítja az előrejelzések pontosságát. A prediktív becslések pontosságának ellenőrzésének legjobb módja, ha az idősort két adathalmazra osztjuk: az egyik a modell felépítésére (azaz betanítására), a másik pedig az érvényesítésre. Az érvényesítési adatkészlet a bemeneti adatkészlet legfrissebb része, és ideális esetben a jövőbeli előrejelzési idővonallal megegyező időkeretet ölel fel. A modell teszteléséhez (érvényesítéséhez) a megjósolt értékeket összehasonlítják a tényleges értékekkel. Vegye figyelembe, hogy az érvényesítés után a modell újraépíthető a teljes idősor felhasználásával, ezért kívánatos a legfrissebb tényleges értékek használata a jövőbeli értékek előrejelzéséhez.
Egy prediktív modell pontosságának mérésekor jellemzően két kérdés merül fel: hogyan határozható meg a prediktív becslés pontossága, és mennyi történelmi adatot kell felhasználni a modell betanításához.
Hogyan határozható meg a prediktív becslés pontossága? Egyes forgatókönyvekben előfordulhat, hogy a tényleges értékek fölé vetített értékek nem kívánatosak (például a beruházási előrejelzésekben). Más helyzetekben a valósnál alacsonyabb előre jelzett értékek pusztító hatásúak lehetnek (például az aukciós tétel legalacsonyabb nyerőárának előrejelzése). De azokban az esetekben, amikor az összes előrejelzéshez becslést szeretne kiszámítani (függetlenül attól, hogy az előrejelzési értékek magasabbak vagy alacsonyabbak a valós értékeknél), kezdheti azzal, hogy számszerűsíti a hibát egyetlen előrejelzésben a definíció segítségével:
hiba = becsült érték - tényleges érték
Ezzel a hibadefinícióval két legnépszerűbb módszer létezik a pontosság mérésére: ez az átlagos abszolút hiba, azaz az átlagos abszolút hiba (MAE) és az átlagos abszolút százalékos hiba, vagy az átlagos abszolút százalékos hiba (MAPE). A MAE módszerben az előrejelzési hibák abszolút értékeit összegzik, majd elosztják az előrejelzések teljes számával. A MAPE módszer az előrejelzéstől való átlagos abszolút eltérést számítja ki százalékban. Ha példákat szeretne látni ezekről és más módszerekről a prediktív becslések minőségének mérésére, egy Excel-sablon (minta prediktív adatokkal és pontossági tényezőkkel) található a Keresleti metrikák diagnosztikai sablon weboldalán (demandplanning.net/DemandMetricsExcelTemp.htm). ).
Mennyi történelmi adatot kell felhasználni a modell betanításához? Ha hosszú múltra visszatekintő idősorral dolgozik, érdemes az összes előzményadatot belefoglalni a modellbe. Néha azonban a további előzmények nem javítják az előrejelzés pontosságát. A múltbeli adatok akár torzíthatják is az előrejelzést, ha a múltbeli feltételek jelentősen eltérnek a jelentől (például a munkaerő jelenlegi és múltbeli összetétele eltérő). Még nem találkoztam olyan képlettel vagy gyakorlati módszerrel, amely azt javasolná, hogy mennyi történelmi adatot kell tartalmaznia, ezért azt javaslom, hogy kezdje az előrejelzési időintervallumok többszörösét meghaladó idősorokkal, majd ellenőrizze a pontosságot. Ezután próbálja meg felfelé vagy lefelé kerekíteni az előzmények számát, és tesztelje újra.
Az idősoros előrejelzés először 2005-ben jelent meg az SSAS-ban. A prediktív értékek kiszámításához a Microsoft Time Series algoritmus egyetlen algoritmust használt: autoregresszív fa kereszt előrejelzéssel (ARTXP), vagy autoregresszív fa kereszt előrejelzéssel. Az ARTXP az autoregressziót a döntési fa adatbányászatával kombinálja, így a predikciós egyenlet bizonyos kritériumok alapján változhat (vagyis felosztható). Például egy előrejelzési modell jobb illeszkedést (és nagyobb előrejelzési pontosságot) biztosít, ha először dátum szerint, majd a független változó értékével osztja fel, amint az a 6. ábrán látható.
.jpg) |
| 6. ábra: Példa egy ARTXP döntési fára az SSAS-ban |
Az SSAS 2008-ban a Microsoft Time Series algoritmus az ARTXP mellett az autoregresszív integrált mozgó átlag (ARIMA) nevű algoritmust is elkezdte használni a hosszú távú előrejelzések kiszámításához. Az ARIMA iparági szabványnak számít, és autoregresszív folyamatok és mozgóátlag modellek kombinációjaként tekinthető. Ezenkívül elemzi a korábbi előrejelzési hibákat a modell javítása érdekében.
Alapértelmezés szerint a Microsoft Time Series algoritmus az ARIMA és az ARTXP algoritmusok eredményeit kombinálja az optimális előrejelzések elérése érdekében. Ha szeretné, ezt a funkciót kikapcsolhatja. Vessünk egy pillantást az SQL Server Books Online (BOL) dokumentációjára:
„Az algoritmus két különböző modellt tanít ugyanazon adatokból: az egyik modell az ARTXP, a másik pedig az ARIMA algoritmust használja. Az algoritmus ezután kombinálja a két modell eredményeit, hogy a legjobb előrejelzést dolgozza ki, változó számú időszeletet lefedve. Mivel az ARTXP algoritmus alkalmasabb rövid távú előrejelzésekre, célszerű egy előrejelzéssorozat elején használni. Ha azonban az előrejelzéshez szükséges időszeletek a jövőbe mennek, akkor az ARIMA algoritmus értelmesebb.”
Amikor idősoros előrejelzéssel dolgozik az SSAS-ban, mindig tartsa szem előtt a következőket:
Ebben a cikkben bemutattam az idősoros előrejelzés alapjait. Figyelembe vettük az alapalgoritmusok néhány részletét is, hogy azok ne legyenek akadályok az idősorok feldolgozásában. Következő lépésként azt javaslom, hogy sajátítsa el az idősoros előrejelző eszközöket az SSAS segítségével. Mintaként szolgálhat egy projekt, amely a jelen cikkben közölt munkanélküliségi adatokat használja. Ezután megtekintheti a TechNet e-oktatóanyagát "Középszintű adatbányászati oktatóanyag (Analysis Services - Data Mining)" a technet.microsoft.com/en-us/library /cc879271.aspx címen.
Az elmúlt évtizedben az üzleti intelligencia (BI) technológiák, például az OLAP széles körben elterjedtek. Ezzel egy időben a Microsoft egy másik BI-technológiát, az adatbányászatot olyan népszerű eszközökbe tolta be, mint a Microsoft SQL Server és a Microsoft Excel. Az adatbányászati technológia azonban még nem vált vezető pozícióvá. Miért? Míg a legtöbb ember gyorsan megérti az adatbányászat alapvető fogalmait, az algoritmusok alapvető részletei elválaszthatatlanul kapcsolódnak a matematikai fogalmakhoz és képletekhez. Nagy "eltérés" van az absztrakt megértés magas szintje és a részletes végrehajtás között. Ennek eredményeként az informatikai szakemberek és az ipari ügyfelek az adatbányászatot "fekete doboznak" tekintik, ami nem segíti elő a technológia széles körű elterjedését. Ez a cikk arra tesz kísérletet, hogy csökkentsem az idősor-előrejelzés "eltéréseit".
A fő cikkben a grafikonok adatai az Egyesült Államok által a munkaképes népességre vonatkozó információkon alapulnak. Munkaügyi Statisztikai Hivatal (http://www.bls.gov/). A BLS az US Census Bureau (BLS) havi felmérése alapján bocsát ki munkanélküliségi adatokat, amelyek extrapolálják a foglalkoztatottak és a munkanélküliek számát. Pontosabban, a BLS a következő képletet alkalmazza:
Munkanélküliségi ráta = munkanélküli/(munkanélküli + foglalkoztatott)
Figyelemre méltó, hogy amikor a munkanélküliségi rátáról van szó, a média általában szezonálisan kiigazított együtthatót közöl. A szezonális kiigazítás az autoregresszív integrált mozgóátlagnak (ARIMA) nevezett általános modell segítségével történik. Ez lényegében ugyanaz az algoritmus, amelyet számos adatbányászati csomagban használnak idősor-előrejelzéshez, beleértve az SQL Server Analysis Services (SSAS) szolgáltatást is. A BLS által használt ARIMA modellről további információkért látogasson el az X-12-ARIMA Seasonal Adjustment Program weboldalára (www.census.gov/srd/www/x12a/). Vegye figyelembe, hogy a cikk mintatervében szezonálisan és nem szezonálisan kiigazított értékeket használtam.