
Buna ziua.
Vreau să vorbesc despre o problemă care m-a interesat foarte mult la un moment dat, și anume problema prognozării seriilor temporale și rezolvarea acestei probleme folosind algoritmul furnici.
În primul rând, pe scurt despre problemă și despre algoritmul în sine:
Prognoza seriei temporale implică faptul că valoarea unei anumite funcții în primele n puncte ale seriei temporale este cunoscută. Folosind aceste informații, este necesar să se prezică valoarea la n+1 puncte din seria temporală. Există multe metode diferite de prognoză, dar astăzi unele dintre cele mai comune sunt metoda Winters și modelul ARIMA. Puteți citi mai multe despre ele.
S-au spus deja destul de multe despre ce este un algoritm de furnică. Pentru cei cărora le este prea lene să urce, de exemplu, Aici, o voi re povesti. Pe scurt, algoritmul furnicilor este o simulare a comportamentului unei colonii de furnici în încercarea lor de a găsi calea cea mai scurtă către o sursă de hrană. Furnicile, atunci când se mișcă, lasă în urmă o urmă de feromoni, care afectează probabilitatea ca furnica să aleagă o anumită cale. Având în vedere că furnicile vor parcurge un drum scurt de mai multe ori în aceeași perioadă de timp, pe ea va rămâne mai mult feromoni. Astfel, în timp, tot mai multe furnici vor alege calea cea mai scurtă către sursa de hrană.
Pentru claritate, voi introduce o poză:
Acum, să trecem direct la rezolvarea problemei de prognoză folosind metoda coloniei de furnici.
Prima problemă cu care ne confruntăm este că trebuie să reprezentăm seria temporală sub forma unui grafic pe care vom rula algoritmul furnici.
Au fost găsite două soluții posibile:
1. Prezentați o serie temporală sub forma unui multigraf în care din fiecare punct din seria temporală puteți merge la fiecare punct cu un set de anumite incremente. (Pentru a ușura sarcina, vom lua valori normalizate în intervalul de la -1 la 1). Aceasta a fost prima abordare pe care am încercat-o. A arătat rezultate bune pe seriile de timp cu dimensiuni reduse, dar pe măsură ce dimensiunea a crescut, atât acuratețea prognozei, cât și performanța au început să scadă brusc, așa că această opțiune a fost abandonată.
2. Prezentați seria de timp ca un set de grafice legate, în care fiecare grafic este responsabil pentru propria sa creștere a valorii seriei de timp. cu alte cuvinte, avem un grafic care este responsabil pentru creșterea -1, -0,9... și așa mai departe până la 1. Pasul, desigur, poate fi redus sau mărit, ceea ce va afecta acuratețea prognozei și intensitatea resurselor sarcinii (În cele din urmă, această opțiune s-a dovedit a fi cea mai de succes.)
Pe acest set de grafice legate a fost lansat (pe fiecare grafic) un algoritm de furnici care a depus feromoni pe marginile corespunzatoare valorilor cunoscute ale seriei de timp. Mai mult, la depunerea feromonului pe graficul i, feromonul a fost depus și pe graficele i-1 și i+1, dar într-o cantitate mult mai mică (în cazul nostru, 1/10 din cantitatea de bază de feromon) astfel, furnicile au identificat cele mai frecvente secvențe de creștere a valorii seriilor temporare și prin depunerea feromonului pe grafice adiacente, eroarea posibilă și zgomotul inițial al seriei de timp au fost nivelate.
Am testat acest algoritm pe serii de timp pregătite artificial cu diferite niveluri de periodicitate și zgomot. Rezultatul a fost dublu. Pe de o parte, la niveluri de zgomot de până la 0,3, algoritmul arată rezultate de predicție ridicate, comparabile cu rezultatele modelului ARIMA. La niveluri de zgomot mai ridicate, există o mare dispersie de rezultate: prognoza este uneori foarte precisă, alteori complet greșită.
În prezent lucrăm la selectarea valorii optime pentru parametrii algoritmului și a unor metode de îmbunătățire a acesteia, despre care voi scrie imediat ce au fost suficient testați.
Mulțumesc tuturor pentru atenție.
Actualizare: Voi încerca să răspund la întrebările care apar.
Un multigraf este un grafic în care fiecare vârf este conectat unul cu celălalt.
Seriile haotice, așa cum este deja scris mai jos, nu sunt aleatorii. Puteți privi imaginile din seria Lorentz în spațiul tridimensional și puteți vedea mișcarea ciclică. Este dificil să determinați pur și simplu această ciclicitate și, la prima vedere, seria pare aleatorie.
Valorile seriilor temporale sunt normalizate pe intervalul -1...1 și înregistrate în grafic. Un grafic este în acest caz un tabel de tranziții de la vârf la vârf. Feromonul se depune pe margini (în celulele tabelului).
În cazul graficelor concatenate, sunt utilizate mai multe tabele, fiecare dintre ele fiind responsabil doar pentru propria sa valoare de tranziție.
În funcție de cantitatea de feromoni dintr-o anumită celulă, una sau alta valoare a seriei de timp este selectată ca rezultat al prognozei.
Algoritmul a fost testat în principal pe seria Lorentz.
Momentan, este prea devreme pentru a spune cât de mai bine sau mai rău este. Se pare că algoritmul este predispus să găsească pseudo-perioade și numărul de perioade false crește pe măsură ce nivelul de zgomot crește.
Pe de altă parte, cu selecția cu succes a parametrilor, precizia prognozei este destul de mare (deviația este de până la 7-10 la sută, ceea ce nu este rău pentru o serie haotică.)
Vom trece la testarea datelor reale mai târziu. Voi încerca să pregătesc și să adaug poze în viitorul apropiat.
Vă mulțumim pentru atenție.
Analiza serii temporale (TSA) este cea mai simplă metodă de reconstrucție a unei relații într-un caz determinist, bazată pe o serie temporală dată. Sarcina principală este extrapolarea (prognoza) - cel mai simplu mod de a prognoza situația pieței. Esența sa este diseminarea tendințelor care s-au dezvoltat în trecut și în viitor.
Multe procese de piață au inerție, care este luată în considerare în previziuni. Pentru o anumită perioadă, probabilitatea unor schimbări în condițiile pieței ar trebui luată în considerare cât mai mult posibil. Se presupune că sistemul evoluează în condiții destul de stabile. Cu cât sistemul este mai mare, cu atât este mai probabil ca parametrii să fie salvați fără modificări, dar nu pentru o perioadă lungă de timp. Se recomandă ca perioada de prognoză să nu depășească 1/3 din durata bazei de timp inițiale.
O serie temporală este o serie de valori numerice obținute la intervale regulate.Principalul punct pe care se bazează utilizarea seriilor temporale într-o întreprindere îl reprezintă factorii care influențează răspunsul sistemului studiat, operând în trecut, prezent și va acţiona în mod similar în viitorul apropiat.
Scopul analizei este de a evalua și identifica factorii pentru a prezice comportamentul ulterioar al sistemului și pentru a dezvolta SD rațional. Prognoza bazată pe AVR este pe termen scurt; în raport cu perioada pentru care este acceptată, caracteristicile fenomenului studiat nu se modifică semnificativ. Majoritatea erorilor de prognoză provin din faptul că prognoza presupune că tendințele din trecut vor continua în viitor. Această ipoteză este rareori justificată în viața economică și socială.
VR poate fi o bază slabă pentru dezvoltarea unei prognoze, astfel încât metodele de prognoză și AVR sunt utilizate pentru prognoza pe termen scurt a proceselor destul de stabile și bine studiate. Perioada de prognoză nu depășește 25-30% din baza de timp inițială. Când se utilizează ecuația de regresie, se efectuează calcule de prognoză pentru estimări optimiste și pesimiste ale parametrilor inițiali. De aici se obtin 2 tipuri de prognoze: optimiste si pesimiste. Estimarea de prognoză obținută pe baza metodelor de prognoză este utilizată ca indicator al valorii dorite a parametrului de prognoză.
VR include:
1) tendință – arată tipul general de modificări, scăderea și creșterea pe termen lung a seriei,
2) fluctuații sezoniere - fluctuații în jurul unei tendințe care apar în mod regulat.
De obicei, fluctuațiile regulate apar într-o perioadă de până la un an. Poate fi urmărit trimestrial, lunar, săptămânal etc. observatii.
3) fluctuații ciclice – apar în perioade de peste un an. Adesea prezente în datele financiare, ele sunt asociate cu scăderi, boom-uri și perioade de stagnare.
4) fluctuații aleatorii - fluctuații imprevizibile în majoritatea realității VR.
Cerințe pentru datele din seria temporală
Toate metodele de prognoză folosesc statistici matematice, deci este necesar ca toate datele să fie comparabile, suficient reprezentate pentru ca modelele să pară omogene și stabile. Neîndeplinirea uneia dintre aceste cerințe face ca utilizarea statisticii matematice să nu aibă sens.
1. Comparabilitatea se realizează ca urmare a aceleiași abordări a observațiilor în diferite etape ale formării unei serii temporale. Datele din serii de timp trebuie să fie exprimate în aceleași unități de măsură, să aibă aceeași etapă de observare, să fie calculate pentru același interval de timp folosind aceeași metodologie, să acopere aceleași elemente aparținând aceluiași teritoriu și aparținând unei populații constante.
Incompatibilitatea datelor se manifestă cel mai adesea în indicatorii de cost. Chiar și în cazurile în care valorile acestor indicatori sunt fixate în prețuri constante. Acest tip de incomparabilitate a seriilor temporale nu poate fi eliminat prin metode pur formale.
2. Reprezentativitatea datelor caracterizat în primul rând prin caracterul complet al datelor prezentate. Se determină un număr suficient de observații în funcție de scopul studiului. Dacă scopul este analiza statistică descriptivă, atunci puteți alege orice interval la discreția dvs. ca interval de timp în studiu. Dacă scopul studiului este de a construi un model de prognoză, atunci numărul de date din seria temporală originală ar trebui să fie de cel puțin 3 ori mai mare decât perioada de prognoză și nu trebuie să fie mai mic de 7 date. În cazul utilizării datelor trimestriale sau lunare pentru a studia sezonalitatea și a prognoza procesele sezoniere, seria temporală inițială trebuie să conțină date trimestriale sau lunare pentru cel puțin 4 ani, chiar dacă prognoza este necesară pentru 1 sau 2 luni.
3.Uniformitate– absența observațiilor anormale atipice, precum și a întreruperilor de tendințe (modificări). Anomalia conduce la o prejudecată a estimărilor și, în consecință, la denaturarea rezultatelor analizei. Formal, anomalia se manifestă ca un salt sau declin puternic urmat de o restabilire aproximativă a nivelului anterior. Au fost dezvoltate diferite criterii standard pentru a diagnostica observațiile anormale.
4. Durabilitate– această proprietate reflectă predominanța regularității asupra aleatoriei în schimbările de nivel și serie. Pe graficele seriilor temporale stabile, un model poate fi văzut chiar și vizual. Iar pe graficele seriilor temporale instabile, modificările sunt prezentate haotic. Prin urmare, căutarea modelelor în astfel de serii cronologice nu are sens.
Modele de serie de timp
Metodele de cercetare statistică se bazează pe ipoteza posibilității de a reprezenta valorile unei serii de timp ca o combinație a mai multor componente, reflectând regularitatea și aleatorietatea dezvoltării. În special, modelele aditive (adaptative) și multiplicative sunt utilizate pentru prognozele pe termen scurt.
1. Adaptiv (aditiv)
Y(t) = T(t) + S(t) + F(t)
t - numărul intervalului de timp
T(t) – tendință de dezvoltare (tendință pe termen lung)
S(t) – componentă sezonieră
E(t) – componenta reziduala
2. Multiplicativ
Y(t) = T(t)*S(t)*F(t)
Dacă amplitudinea undei sezoniere este uniform constantă, se recomandă utilizarea unui model aditiv. La modificarea amplitudinii valului sezonier în conformitate cu tendința nivelului mediu, se utilizează un model multiplicativ. Uneori sunt folosite modele de tip mixt; acestea dau rezultate mai precise, dar sunt prost interpretate din punct de vedere al conținutului. Utilizarea modelului multiplicativ se datorează faptului că în unele serii temporale valoarea componentei sezoniere reprezintă o anumită proporție din valoarea trendului. Practica arată că în cazurile în care fluctuațiile sezoniere ale procesului studiat sunt mari și nu foarte stabile, modelul multiplicativ dă rezultate slabe. Componenta sezonieră caracterizează fluctuații stabile și intraanuale ale nivelurilor - se manifestă în unii indicatori prezentați prin date trimestriale sau lunare.
În modelele cu componente aditive și multiplicative, procedura generală de analiză este aproximativ aceeași.
Trebuie sa fac:
1) calculul valorilor componentelor sezoniere
2) scăderea componentei sezoniere din valorile reale - acest proces se numește desezonalizare (eliminarea sezonalității)
3) calculul erorilor ca diferență între valorile actuale și cele de tendință
4) calculul abaterii medii sau al erorii standard
Se folosește și prognoza modele de curbă de creștere.
Curbele de creștere sunt funcții matematice concepute pentru alinierea analitică a unei serii de timp.
Următoarele funcții sunt utilizate pentru a descrie curbele de creștere
2. Parabola Y(t) = a+bt =ct 2
3. Hiperbola Y(t) = a +b/t
4. Putere
5. Demonstrativ
6. Logaritmic
7. Curba Johnson
8. Expozant modificat
Netezirea seriilor temporale
Identificarea tendinței principale de dezvoltare se numește nivelare sau netezire a seriei de timp. Metodele de identificare a tendinței principale sunt metodele de egalizare.
Una dintre cele mai simple metode de detectare a unei tendințe generale în dezvoltarea unui fenomen este mărirea intervalului unei serii de timp. Pentru a identifica tendințele de dezvoltare, se utilizează metoda mediei mobile sau metoda de netezire exponențială. Ambele metode sunt subiective în ceea ce privește alegerea parametrilor de netezire. Și tocmai în alegerea corectă a parametrilor se manifestă intuiția cercetătorului.
Metoda mediei mobile– este extrem de subiectivă, iar rezultatele de netezire sunt foarte influențate de durata perioadei de netezire. Pentru perioade scurte nu este posibil să se identifice componenta de trend. Pe perioade lungi, la sfârșitul intervalului analizat apar pierderi semnificative de date.
O medie mobilă de ordin L este o serie temporală constând din media aritmetică și media aritmetică L în valorile învecinate ale funcției Y pentru toate valorile de timp posibile. Ca L - un număr impar, 3, 5,7 - trei puncte, cinci puncte și șapte puncte.
Schema în trei puncte: valoarea medie va fi calculată pe baza a 3 valori Yi, dintre care una se referă la perioada trecută, a doua la cea dorită și 3 la perioada viitoare. Dacă i = 1 nu există o valoare trecută, atunci la primul punct este imposibil să se calculeze valoarea netezită. Dacă i = 2, atunci valoarea medie va fi media aritmetică.
În ultimul punct al intervalului inițial, nici media mobilă nu poate fi calculată din cauza absenței unei valori viitoare în raport cu cea calculată.
Metoda de netezire exponențială– spre deosebire de media mobilă, poate fi folosită pentru previziuni pe termen scurt ale tendințelor viitoare cu o perioadă în avans. De aceea metoda are un avantaj clar față de cea anterioară.
Algoritmul pentru calcularea valorilor netezite în orice punct al seriei se bazează pe 3 valori: valoarea observată a lui Yi la un punct dat, valoarea netezită calculată pentru punctul anterior din serie și câțiva coeficienți de netezire predeterminați care sunt constanți. pe tot parcursul seriei.
Fi = α*Yi +(α-1)*Fi
Yi este valoarea reală a acelui punct din serie.
Valoare netezită pentru punctul anterior din serie - (alfa-1)
Alfa poate lua orice valoare de la 0 la 1, dar este de obicei limitată în practică la intervalul de la 0,2 la 0,5
metoda Holt. L t =k*Yt +(1-k)*(L t-1 -T t-1), unde
L t – valoarea netezită pentru perioada curentă;
K – coeficientul de netezire în serie;
Y t – valoarea curentă a seriei (de exemplu, volumul vânzărilor);
L t-1 – valoarea netezită pentru perioada anterioară;
T t-1 – valoarea tendinței pentru perioada anterioară.
Cele trei note anterioare descriu modele de regresie care vă permit să preziceți răspunsul pe baza valorilor variabilelor explicative. În această notă, arătăm cum să folosiți aceste modele și alte metode statistice pentru a analiza datele colectate pe intervale de timp succesive. În funcție de caracteristicile fiecărei companii menționate în scenariu, vom lua în considerare trei abordări alternative ale analizei seriilor temporale.
Materialul va fi ilustrat cu un exemplu transversal: prognozarea veniturilor a trei companii. Imaginați-vă că lucrați ca analist la o mare companie financiară. Pentru a evalua perspectivele de investiții ale clienților tăi, trebuie să prezici câștigurile a trei companii. Pentru a face acest lucru, ați colectat date despre trei companii care vă interesează - Eastman Kodak, Cabot Corporation și Wal-Mart. Întrucât companiile diferă în ceea ce privește tipul de activitate comercială, fiecare serie de timp are propriile caracteristici unice. Prin urmare, pentru prognoză trebuie utilizate diferite modele. Cum să alegi cel mai bun model de prognoză pentru fiecare companie? Cum se evaluează perspectivele de investiție pe baza rezultatelor prognozei?
Discuția începe cu o analiză a datelor anuale. Sunt demonstrate două metode de netezire a unor astfel de date: medie mobilă și netezire exponențială. Apoi demonstrează cum se calculează o tendință folosind cele mai mici pătrate și metode de prognoză mai avansate. În cele din urmă, aceste modele sunt extinse la serii de timp construite din date lunare sau trimestriale.
Descărcați nota în sau format, exemple în format
Prognoza în afaceri
Deoarece condițiile economice se schimbă în timp, managerii trebuie să anticipeze impactul pe care aceste schimbări îl vor avea asupra companiei lor. Una dintre metodele de a asigura o planificare corectă este prognoza. În ciuda numărului mare de metode dezvoltate, toate urmăresc același scop - de a prezice evenimente care vor avea loc în viitor pentru a le ține cont la elaborarea planurilor și strategiilor de dezvoltare a companiei.
Societatea modernă experimentează în mod constant nevoia de prognoză. De exemplu, pentru a face politica corectă, membrii guvernului trebuie să prognozeze nivelurile șomajului, inflației, producției industriale, impozitului pe venit al persoanelor fizice și al corporațiilor. Pentru a determina cerințele de echipamente și personal, directorii companiilor aeriene trebuie să prezică corect volumele de trafic aerian. Pentru a crea suficient spațiu în cămin, administratorii colegiilor sau universităților vor să știe câți elevi vor intra în școala lor anul viitor.
Există două abordări general acceptate pentru prognoză: calitativă și cantitativă. Metodele de prognoză calitativă sunt deosebit de importante atunci când datele cantitative nu sunt disponibile cercetătorului. De regulă, aceste metode sunt foarte subiective. Dacă datele privind istoricul subiectului de studiu sunt disponibile pentru statistician, trebuie utilizate metode de prognoză cantitativă. Aceste metode vă permit să preziceți starea unui obiect în viitor pe baza datelor despre trecutul său. Metodele de prognoză cantitativă se împart în două categorii: analiza seriilor temporale și metodele de analiză cauză-efect.
serii de timp este un set de date numerice obţinute pe perioade consecutive de timp. Metoda de analiză a seriilor de timp vă permite să preziceți valoarea unei variabile numerice pe baza valorilor sale trecute și prezente. De exemplu, prețurile zilnice ale acțiunilor la Bursa de Valori din New York formează o serie de timp. Un alt exemplu de serie temporală sunt valorile lunare ale indicelui prețurilor de consum, valorile trimestriale ale produsului intern brut și veniturile anuale din vânzări ale unei companii.
Metode de analiză a relațiilor cauză-efect vă permit să determinați ce factori afectează valorile variabilei prezise. Acestea includ metode de analiză de regresie multiplă cu variabile întârziate, modelare econometrică, analiza indicatorilor conducători, metode de analiză a indicilor de difuzie și alți indicatori economici. Vom vorbi doar despre metodele de prognoză bazate pe analiza timpului. s x rânduri.
Componentele modelului de timp multiplicativ clasic s x rânduri
Principala ipoteză care stă la baza analizei seriilor de timp este următoarea: factorii care afectează obiectul studiat în prezent și trecut îl vor afecta și în viitor. Astfel, obiectivele principale ale analizei seriilor temporale sunt identificarea și evidențierea factorilor importanți pentru prognoză. Pentru a atinge acest obiectiv, au fost dezvoltate multe modele matematice pentru a studia fluctuațiile componentelor incluse într-un model de serie de timp. Probabil cel mai comun este modelul multiplicativ clasic pentru datele anuale, trimestriale și lunare. Pentru a demonstra modelul clasic de serie de timp multiplicativă, luați în considerare datele privind venitul real al companiei Wm. Wrigley Jr.. Companie pentru perioada 1982-2001 (Fig. 1).
Orez. 1. Graficul venitului brut real al lui Wm. Wrigley Jr.. Companie (milioane de dolari la prețuri curente) pentru perioada 1982-2001
După cum putem observa, de-a lungul a 20 de ani, venitul brut real al companiei a avut o tendință de creștere. Această tendință pe termen lung se numește tendință. Tendinţă nu este singura componentă a seriei temporale. În plus, datele au componente ciclice și neregulate. Ciclic componentă descrie modul în care datele fluctuează în sus și în jos, corelând adesea cu ciclurile de afaceri. Lungimea sa variază de la 2 la 10 ani. De asemenea, intensitatea sau amplitudinea componentei ciclice nu este constantă. În unii ani, datele pot fi mai mari decât valoarea prezisă de tendință (adică, aproape de vârful ciclului), iar în alți ani - mai mici (adică, la partea de jos a ciclului). Orice date observate care nu se află pe o curbă de tendință și nu se supune unei dependențe ciclice se numesc neregulate sau componente aleatorii. Dacă datele sunt înregistrate zilnic sau trimestrial, există o componentă suplimentară numită sezonier. Toate componentele seriilor de timp tipice pentru aplicațiile economice sunt prezentate în Fig. 2.
Orez. 2. Factori care influenţează seriile de timp
Modelul clasic de serie de timp multiplicativă afirmă că orice valoare observată este produsul componentelor enumerate. Dacă datele sunt anuale, observație Yi, corespunzătoare i an, se exprimă prin ecuația:
(1) Y eu = T i* C i* eu i
Unde T i- valoarea tendinței, C i i- al-lea an, eu i i- al-lea an.
Dacă datele sunt măsurate lunar sau trimestrial, observație Y eu, corespunzătoare perioadei i-a, se exprimă prin ecuația:
(2) Y i = T i *S i *C i *I i
Unde T i- valoarea tendinței, S i- valoarea componentei sezoniere în i-a-a perioadă, C i- valoarea componentei ciclice în i-a-a perioadă, eu i- valoarea componentei aleatoare în i-a perioada.
În prima etapă a analizei seriilor temporale, se construiește un grafic de date și se identifică dependența acestuia de timp. În primul rând, trebuie să aflați dacă există o creștere sau o scădere pe termen lung a datelor (adică, o tendință) sau dacă seria temporală oscilează în jurul unei linii orizontale. Dacă nu există nicio tendință, atunci metoda mediilor mobile sau netezirea exponențială poate fi utilizată pentru a netezi datele.
Netezirea seriilor temporale anuale
În scenariu am menționat Corporația Cabot. Cu sediul central în Boston, Massachusetts, este specializată în producția și vânzarea de produse chimice, materiale de construcție, chimicale fine, semiconductori și gaze naturale lichefiate. Compania are 39 de fabrici în 23 de țări. Valoarea de piață a companiei este de aproximativ 1,87 miliarde de dolari. Acțiunile sale sunt listate la Bursa de Valori din New York sub abrevierea SVT. Venitul companiei pentru perioada specificată este prezentat în Fig. 3.

Orez. 3. Veniturile companiei Cabot Corporation în 1982–2001 (miliarde de dolari)
După cum putem vedea, tendința pe termen lung de creștere a câștigurilor este ascunsă de un număr mare de fluctuații. Astfel, analiza vizuală a graficului nu ne permite să spunem că datele au o tendință. În astfel de situații, puteți aplica metode de netezire a mediei mobile sau exponențiale.
Medii mobile. Metoda mediei mobile este foarte subiectivă și depinde de durata perioadei L, selectat pentru calcularea valorilor medii. Pentru a elimina fluctuațiile ciclice, durata perioadei trebuie să fie un multiplu întreg al duratei medii a ciclului. Medii mobile pentru o perioadă selectată de lungime L, formează o secvență de valori medii calculate pentru secvențe de lungime L. Mediile mobile sunt indicate prin simboluri MA(L).
Să presupunem că dorim să calculăm medii mobile pe cinci ani din datele măsurate peste n= 11 ani. Deoarece L= 5, mediile mobile pe cinci ani formează o succesiune de medii calculate pe cinci valori consecutive ale seriei de timp. Prima dintre mediile mobile pe cinci ani este calculată prin însumarea datelor pentru primii cinci ani, apoi împărțind la cinci:
![]()
A doua medie mobilă pe cinci ani este calculată prin însumarea datelor pentru anii 2 până la 6, apoi împărțind la cinci:
![]()
Acest proces continuă până când se calculează o medie mobilă pentru ultimii cinci ani. Când lucrați cu date anuale, ar trebui să presupuneți numărul L(lungimea perioadei alese pentru calcularea mediilor mobile) impar. În acest caz, este imposibil să se calculeze mediile mobile pentru prima ( L– 1)/2 și ultimul ( L– 1)/2 ani. Prin urmare, atunci când se lucrează cu medii mobile pe cinci ani, nu este posibil să se efectueze calcule pentru primii doi și ultimii doi ani. Anul pentru care se calculează media mobilă trebuie să fie la mijlocul unei perioade de lungime L. Dacă n= 11, a L= 5, prima medie mobilă ar trebui să corespundă celui de-al treilea an, al doilea celui de-al patrulea, iar ultima al nouălea. În fig. Figura 4 arată mediile mobile pe 3 și 7 ani calculate pentru câștigurile Cabot Corporation din 1982 până în 2001.

Orez. 4. Grafice ale mediilor mobile pe 3 și 7 ani calculate pentru câștigurile Cabot Corporation
Rețineți că atunci când se calculează mediile mobile pe trei ani, valorile observate corespunzătoare primului și ultimului an sunt ignorate. În mod similar, atunci când se calculează mediile mobile pe șapte ani, nu există rezultate pentru primii și ultimii trei ani. În plus, mediile mobile pe șapte ani netezesc seria temporală mult mai mult decât mediile mobile pe trei ani. Acest lucru se datorează faptului că media mobilă pe șapte ani corespunde unei perioade mai lungi. Din păcate, cu cât perioada este mai lungă, cu atât mai puține medii mobile pot fi calculate și prezentate pe grafic. Prin urmare, nu este recomandabil să alegeți mai mult de șapte ani pentru calcularea mediilor mobile, deoarece prea multe puncte vor cădea de la începutul și de la sfârșitul graficului, ceea ce va distorsiona forma seriei temporale.
Netezire exponențială. Pentru a identifica tendințele pe termen lung care caracterizează modificările datelor, pe lângă mediile mobile, se folosește metoda de netezire exponențială. Această metodă permite, de asemenea, realizarea de prognoze pe termen scurt (într-o perioadă), atunci când prezența tendințelor pe termen lung rămâne sub semnul întrebării. Datorită acestui fapt, metoda de netezire exponențială are un avantaj semnificativ față de metoda mediei mobile.
Metoda de netezire exponențială își primește numele dintr-o secvență de medii mobile ponderate exponențial. Fiecare valoare din această secvență depinde de toate valorile observate anterior. Un alt avantaj al metodei de netezire exponențială față de metoda mediei mobile este că atunci când se folosește cea din urmă, unele valori sunt eliminate. Cu netezirea exponențială, ponderile atribuite valorilor observate scad în timp, astfel încât, atunci când calculul este finalizat, cele mai comune valori vor primi cea mai mare pondere, iar valorile rare vor primi cea mai mică pondere. În ciuda numărului mare de calcule, Excel vă permite să implementați metoda de netezire exponențială.
O ecuație care vă permite să neteziți o serie temporală într-o perioadă de timp arbitrară i, conține trei termeni: valoarea curentă observată Yi, aparținând seriei temporale, valoarea anterioară netezită exponențial Ei –1 și greutatea atribuită W.
(3) E 1 = Y 1 E i = WY i + (1 – W)E i–1 , i = 2, 3, 4, …
Unde Ei– valoarea seriei netezite exponențial calculată pentru i-a-a perioadă, E i –1 – valoarea seriei netezite exponențial calculată pentru ( i– a 1-a perioadă, Y eu– valoarea observată a seriei temporale în i-a-a perioadă, W– greutate subiectivă sau coeficient de netezire (0< W < 1).
Alegerea factorului de netezire, sau ponderea atribuită membrilor seriei, este fundamentală deoarece afectează direct rezultatul. Din păcate, această alegere este oarecum subiectivă. Dacă cercetătorul dorește pur și simplu să excludă fluctuațiile ciclice sau aleatorii nedorite din seria temporală, ar trebui selectate valori mici W(aproape de zero). Pe de altă parte, dacă seria temporală este utilizată pentru prognoză, este necesar să se selecteze o pondere mare W(aproape de unitate). În primul caz, tendințele pe termen lung din seria temporală sunt clar vizibile. În al doilea caz, acuratețea prognozei pe termen scurt crește (Fig. 5).

Orez. 5 Grafice ale seriilor temporale netezite exponențial (W=0,50 și W=0,25) pentru datele privind veniturile Cabot Corporation din 1982 până în 2001; Pentru formule de calcul, consultați fișierul Excel
Valoarea netezită exponențial obținută pentru i-interval de timp, poate fi folosit ca o estimare a valorii prezise în ( i+1)-al-lea interval:
![]()
Pentru a prezice câștigurile Cabot Corporation din 2002 pe baza unei serii cronologice netezite exponențial corespunzătoare ponderii W= 0,25, poate fi utilizată valoarea netezită calculată pentru 2001. Din fig. Figura 5 arată că această valoare este egală cu 1651,0 milioane USD. Când devin disponibile date despre venitul companiei în 2002, putem aplica ecuația (3) și putem prezice nivelul venitului în 2003 folosind valoarea netezită a venitului în 2002:
Pachet de analize Excel poate crea un grafic de netezire exponențială cu un singur clic. Treceți prin meniu Date → Analiza datelorși selectați opțiunea Netezire exponențială(Fig. 6). În fereastra care se deschide Netezire exponențială setați parametrii. Din păcate, procedura vă permite să construiți o singură serie netezită, așa că dacă doriți să vă „jucați” cu parametrul W, repetați procedura.

Orez. 6. Trasarea unui grafic de netezire exponențială utilizând pachetul de analiză
Cele mai mici pătrate tendințe și prognoză
Dintre componentele unei serii temporale, tendința este cel mai des studiată. Este tendința care ne permite să facem prognoze pe termen scurt și pe termen lung. Pentru a identifica o tendință pe termen lung într-o serie de timp, se construiește de obicei un grafic în care datele observate (valorile variabilei dependente) sunt reprezentate pe axa verticală și intervalele de timp (valorile variabilei independente) sunt trasate pe axa orizontală. În această secțiune, descriem procedura de identificare a tendințelor liniare, pătratice și exponențiale folosind metoda celor mai mici pătrate.
Model de tendință liniară este cel mai simplu model folosit pentru prognoză: Y eu = β 0 + β 1 X i + εi. Ecuația de tendință liniară:
![]()
Pentru un nivel de semnificație dat α, ipoteza nulă este respinsă dacă testul t-statisticile sunt mai mari decât nivelul critic superior sau mai mic decât nivelul critic inferior t-distribuţii. Cu alte cuvinte, regula decisivă se formulează astfel: dacă t > tU sau t < tL, ipoteza nulă H 0 este respinsă, în caz contrar ipoteza nulă nu este respinsă (Fig. 14).

Orez. 14. Arii de respingere a ipotezei pentru un criteriu cu două laturi pentru semnificația parametrului autoregresiv A r, având ordinul cel mai înalt
Dacă ipoteza nulă ( A r= 0) nu este respinsă, ceea ce înseamnă că modelul selectat conține prea mulți parametri. Criteriul vă permite să renunțați la termenul principal al modelului și să estimați modelul de ordine autoregresiv р–1. Această procedură trebuie continuată până la ipoteza nulă H 0 nu va fi respins.
Pentru a demonstra modelarea autoregresivă, să revenim la analiza seriilor de timp a câștigurilor reale ale Wm. Wrigley Jr. În fig. Figura 15 prezintă datele necesare pentru a construi modele autoregresive de ordinul întâi, al doilea și al treilea. Pentru a construi un model de ordinul trei, sunt necesare toate coloanele acestui tabel. La construirea unui model autoregresiv de ordinul doi, ultima coloană este ignorată. La construirea unui model autoregresiv de ordinul întâi, ultimele două coloane sunt ignorate. Astfel, la construirea modelelor autoregresive de ordinul întâi, al doilea și al treilea, din 20 de variabile, una, două și, respectiv, trei sunt excluse.

Selectarea celui mai precis model autoregresiv începe cu un model de ordinul trei. Pentru o funcționare corectă Pachet de analize urmează ca interval de intrare Y indicați intervalul B5:B21 și intervalul de intrare pentru X– C5:E21. Datele de analiză sunt prezentate în Fig. 16.

Să verificăm semnificația parametrului A 3, care are cel mai înalt nivel. Scorul lui a 3 este -0,006 (celula C20 în Fig. 16), iar eroarea standard este 0,326 (celula D20). Pentru a testa ipotezele H 0: A 3 = 0 și H 1: A 3 ≠ 0, calculăm t-statistici:

t-criteriile cu n–2p–1 = 20–2*3–1 = 13 grade de libertate sunt egale cu: tL= STUDENT.INR(0,025, 13) = -2,160; tU\u003d STUDENT.INR (0,975, 13) \u003d +2,160. Din –2.160< t = –0,019 < +2,160 и R= 0,985 > α = 0,05, ipoteza nulă H 0 nu poate fi respins. Prin urmare, parametrul de ordinul trei nu este semnificativ statistic în modelul autoregresiv și ar trebui eliminat.
Să repetăm analiza pentru un model autoregresiv de ordinul doi (Fig. 17). Estimarea celui mai mare parametru de ordin a 2= –0,205, iar eroarea sa standard este 0,276. Pentru a testa ipotezele H 0: A 2 = 0 și H 1: A 2 ≠ 0, calculăm t-statistici:


La nivelul de semnificație α = 0,05, valorile critice ale două fețe t-criteriile cu n–2p–1 = 20–2*2–1 = 15 grade de libertate sunt egale cu: tL=STUDENT.OBR(0,025,15) = –2,131; tU=STUDENT.OBR(0,975,15) = +2,131. Din -2.131< t = –0,744 < –2,131 и R= 0,469 > α = 0,05, ipoteză nulă H 0 nu poate fi respins. Prin urmare, parametrul de ordinul doi nu este semnificativ statistic și ar trebui eliminat din model.
Să repetăm analiza pentru modelul autoregresiv de ordinul întâi (Fig. 18). Estimarea parametrului cu cel mai mare ordin, a 1= 1,024 și eroarea sa standard este 0,039. Pentru a testa ipotezele H 0: A 1 = 0 și H 1: A 1 ≠ 0, calculăm t-statistici:


La nivelul de semnificație α = 0,05, valorile critice ale două fețe t-criteriile cu n–2p–1 = 20–2*1–1 = 17 grade de libertate sunt egale cu: tL=STUDENT.OBR(0,025,17) = –2,110; tU=STUDENT.OBR(0,975,17) = +2,110. Din –2.110< t = 26,393 < –2,110 и R = 0,000 < α = 0,05, нулевую гипотезу H 0 ar trebui respins. Prin urmare, parametrul de ordinul întâi este semnificativ statistic și nu ar trebui eliminat din model. Deci, modelul autoregresiv de ordinul întâi aproximează datele originale mai bine decât altele. Folosind estimări un 0 = 18,261, a 1= 1,024 și valoarea seriei temporale pentru ultimul an - Y 20 = 1.371,88, putem prezice valoarea venitului real al companiei Wm. Wrigley Jr. Compania in 2002:
Selectarea unui model de prognoză adecvat
Mai sus au fost descrise șase metode de prognoză a valorilor seriilor temporale: modele de tendințe liniare, pătratice și exponențiale și modele autoregresive de ordinul întâi, al doilea și al treilea. Există un model optim? Care dintre cele șase modele descrise ar trebui utilizat pentru a prezice valoarea unei serii de timp? Mai jos sunt patru principii care ar trebui să vă ghideze atunci când alegeți un model de prognoză adecvat. Aceste principii se bazează pe estimări ale preciziei modelului. Se presupune că valorile unei serii temporale pot fi prezise prin studierea valorilor sale anterioare.
Principii pentru selectarea modelelor pentru prognoză:
Analiza reziduurilor. Amintiți-vă că restul este diferența dintre valorile prezise și cele observate. După ce ați construit un model pentru o serie de timp, ar trebui să calculați reziduurile pentru fiecare dintre ele n intervale. După cum se arată în Fig. 19, Panoul A, dacă modelul este adecvat, reziduurile reprezintă componenta aleatorie a seriei de timp și, prin urmare, sunt distribuite neregulat. Pe de altă parte, așa cum se arată în panourile rămase, dacă modelul nu este adecvat, reziduurile pot avea o relație sistematică care nu ia în considerare nici tendința (panoul B), nici ciclica (panoul C), nici sezonieră. componentă (Panoul D).

Orez. 19. Analiza reziduurilor
Măsurarea erorilor reziduale absolute și pătratice medii. Dacă analiza reziduurilor nu permite determinarea unui singur model adecvat, se pot folosi alte metode bazate pe estimarea mărimii erorii reziduale. Din păcate, statisticienii nu au ajuns la un consens cu privire la cea mai bună estimare a erorilor reziduale ale modelelor utilizate pentru prognoză. Pe baza principiului celor mai mici pătrate, puteți mai întâi să efectuați o analiză de regresie și să calculați eroarea standard a estimării S XY. Atunci când se analizează un model specific, această valoare este suma diferențelor pătrate dintre valorile reale și cele prezise ale seriei de timp. Dacă modelul aproximează perfect valorile seriei de timp în momente anterioare, eroarea standard a estimării este zero. Pe de altă parte, dacă modelul face o treabă proastă de aproximare a valorilor seriei de timp în momente anterioare, eroarea standard a estimării este mare. Astfel, prin analizarea adecvării mai multor modele, este posibil să se selecteze un model care are o eroare standard minimă de estimare S XY .
Principalul dezavantaj al acestei abordări este exagerarea erorilor la prezicerea valorilor individuale. Cu alte cuvinte, orice diferență mare între cantități YiȘi Ŷ i Când se calculează suma erorilor pătrate, SSE este pătrat, adică crește. Din acest motiv, mulți statisticieni preferă să utilizeze abaterea medie absolută (MAD) pentru a evalua caracterul adecvat al unui model de prognoză:

Atunci când se analizează modele specifice, valoarea MAD este media valorilor absolute ale diferențelor dintre valorile reale și cele prezise ale seriei de timp. Dacă modelul aproximează perfect valorile seriei de timp în momentele anterioare, abaterea medie absolută este zero. Pe de altă parte, dacă modelul nu aproximează bine astfel de valori ale seriei temporale, abaterea medie absolută este mare. Astfel, analizând adecvarea mai multor modele, este posibil să se selecteze modelul care are abaterea medie absolută minimă.
Principiul economiei. Dacă analiza erorilor standard ale estimărilor și a abaterilor medii absolute nu permite determinarea modelului optim, puteți utiliza a patra metodă, bazată pe principiul parcimoniei. Acest principiu prevede că dintre mai multe modele egale ar trebui să se aleagă pe cel mai simplu.
Dintre cele șase modele de prognoză discutate în capitol, cele mai simple sunt modelele de regresie liniară și pătratică, precum și un model autoregresiv de ordinul întâi. Alte modele sunt mult mai complexe.
Compararea a patru metode de prognoză. Pentru a ilustra procesul de alegere a modelului optim, să revenim la seria temporală constând din valorile venitului real al companiei Wm. Wrigley Jr. companie. Să comparăm patru modele: model liniar, pătratic, exponențial și autoregresiv de ordinul întâi. (Modelele autoregresive de ordinul al doilea și al treilea îmbunătățesc doar puțin acuratețea prognozării valorilor unei anumite serii de timp, astfel încât acestea pot fi ignorate.) În Fig. Figura 20 prezintă grafice reziduale generate prin analiza a patru metode de prognoză folosind Pachet de analize Excela. Ar trebui să fiți atenți când trageți concluzii din aceste grafice, deoarece seria temporală conține doar 20 de puncte. Pentru metodele de construcție, consultați foaia corespunzătoare a fișierului Excel.

Orez. 20. Grafice ale reziduurilor construite din analiza a patru metode de prognoză folosind Pachet de analize excela
Niciun model, altul decât modelul autoregresiv de ordinul întâi, nu ține cont de componenta ciclică. Acest model este cel care aproximează cel mai bine observațiile și se caracterizează prin cea mai puțin sistematică structură. Deci, o analiză a reziduurilor tuturor celor patru metode a arătat că modelul autoregresiv de ordinul întâi este cel mai bun, în timp ce modelele liniare, pătratice și exponențiale au mai puțină acuratețe. Pentru a verifica acest lucru, să comparăm erorile reziduale ale acestor metode (Fig. 21). Metoda de calcul poate fi găsită prin deschiderea fișierului Excel. În fig. 21 sunt valorile reale Y eu(coloană Venitul real), valorile prezise Ŷ i, precum și restul ei pentru fiecare dintre cele patru modele. În plus, sunt afișate valorile SYXȘi NEBUN. Pentru toate cele patru modele de cantități s SYXȘi NEBUN cam la fel. Modelul exponențial este relativ mai rău, în timp ce modelele liniare și pătratice sunt superioare ca precizie. După cum era de așteptat, cele mai mici valori SYXȘi NEBUN are un model autoregresiv de ordinul întâi.

Orez. 21. Comparația a patru metode de prognoză folosind indicatorii S YX și MAD
După ce ați ales un model specific de prognoză, trebuie să monitorizați cu atenție modificările ulterioare din seria temporală. Printre altele, un astfel de model este creat pentru a prezice corect valorile unei serii temporale în viitor. Din păcate, astfel de modele de prognoză nu țin cont de schimbările în structura seriei temporale. Este absolut necesar să se compare nu numai eroarea reziduală, ci și acuratețea prognozării valorilor viitoare ale seriilor temporale obținute folosind alte modele. Prin măsurarea noii valori Yiîn intervalul de timp observat, acesta trebuie imediat comparat cu valoarea prezisă. Dacă diferența este prea mare, modelul de prognoză ar trebui revizuit.
Prognoza timpului s serie x bazată pe date sezoniere
Până acum am studiat serii cronologice formate din date anuale. Cu toate acestea, multe serii cronologice constau din cantități măsurate trimestrial, lunar, săptămânal, zilnic și chiar orar. După cum se arată în Fig. 2, dacă datele sunt măsurate lunar sau trimestrial, trebuie luată în considerare componenta sezonieră. În această secțiune, vom analiza metodele care ne permit să prezicem valorile unor astfel de serii cronologice.
Scenariul descris la începutul capitolului a implicat Wal-Mart Stores, Inc. Capitalizarea de piață a companiei este de 229 de miliarde de dolari. Acțiunile sale sunt listate la Bursa de Valori din New York sub abrevierea WMT. Anul fiscal al companiei se încheie la 31 ianuarie, astfel că al patrulea trimestru din 2002 include noiembrie și decembrie 2001, precum și ianuarie 2002. Seria temporală a veniturilor trimestriale ale companiei este prezentată în Fig. 22.

Orez. 22. Veniturile trimestriale ale Wal-Mart Stores, Inc. (milioane de dolari)
Pentru serii trimestriale precum aceasta, modelul multiplicativ clasic, pe lângă componentele de tendință, ciclice și aleatorii, conține o componentă sezonieră: Y eu = T i* S i* C i* eu i
Predicția menstruației și a timpului s serie x folosind metoda celor mai mici pătrate. Modelul de regresie, care include o componentă sezonieră, se bazează pe o abordare combinată. Pentru a calcula tendința, se folosește metoda celor mai mici pătrate descrisă mai devreme, iar pentru a lua în considerare componenta sezonieră se folosește o variabilă categorială (pentru mai multe detalii, vezi secțiunea Modele de regresie variabilă simulată și efecte de interacțiune). Un model exponențial este utilizat pentru a aproxima seriile de timp ținând cont de componentele sezoniere. Într-un model care aproximează o serie de timp trimestrială, am avut nevoie de trei variabile fictive pentru a contabiliza patru trimestre Î 1, Î 2Și Q 3, iar în modelul seriei temporale lunare, 12 luni sunt reprezentate folosind 11 variabile fictive. Deoarece aceste modele folosesc variabila log ca răspuns Y eu, dar nu Y eu, pentru a calcula coeficienții reali de regresie, este necesar să se efectueze o transformare inversă.
Pentru a ilustra procesul de construire a unui model care aproximează o serie temporală trimestrială, să revenim la câștigurile Wal-Mart. Parametrii modelului exponenţial obţinuţi utilizând Pachet de analize Excel sunt prezentate în fig. 23.

Orez. 23. Analiza de regresie a câștigurilor trimestriale ale Wal-Mart Stores, Inc.
Se poate observa că modelul exponențial aproximează destul de bine datele originale. Coeficient de corelație mixt r 2 egal cu 99,4% (celule J5), coeficient de corelație mixt ajustat - 99,3% (celule J6), test F-statistici - 1.333,51 (celule M12) și R-valoarea este 0,0000. La un nivel de semnificație de α = 0,05, fiecare coeficient de regresie în modelul clasic de serie de timp multiplicativă este semnificativ statistic. Aplicându-le operația de potențare, obținem următorii parametri:

Cote ![]() sunt interpretate după cum urmează.
sunt interpretate după cum urmează.
Utilizarea coeficienților de regresie b i, puteți prezice veniturile generate de o companie într-un anumit trimestru. De exemplu, să prezicem veniturile unei companii pentru al patrulea trimestru al anului 2002 ( Xi = 35):
jurnal = b 0 + b 1 Xi = 4,265 + 0,016*35 = 4,825
= 10 4,825 = 66 834
Astfel, conform prognozei, în trimestrul al patrulea al anului 2002 compania ar fi trebuit să înregistreze venituri egale cu 67 de miliarde de dolari (este puțin probabil ca prognoza să fie exactă la cel mai apropiat milion). Pentru a extinde prognoza la o perioadă de timp din afara seriei temporale, de exemplu, până în primul trimestru al anului 2003 ( Xi = 36, Î 1= 1), trebuie efectuate următoarele calcule:
Buturuga Ŷ i = b 0 + b 1Xi + b 2 Q 1 = 4,265 + 0,016*36 – 0,093*1 = 4,748
10 4,748 = 55 976
Indici
Indicii sunt utilizați ca indicatori care răspund la schimbările din situația economică sau din activitatea de afaceri. Există numeroase tipuri de indici, cum ar fi indici de preț, indici cantitativi, indici de valoare și indici sociologici. În această secțiune vom lua în considerare doar indicele prețurilor. Index- valoarea unui indicator economic (sau grup de indicatori) la un anumit moment în timp, exprimată ca procent din valoarea acestuia la momentul de bază în timp.
Indice de pret. Un indice de preț simplu reflectă modificarea procentuală a prețului unui bun (sau al unui grup de bunuri) într-o anumită perioadă de timp în comparație cu prețul acelui bun (sau al grupului de bunuri) la un anumit moment în timp din trecut. Când calculați un indice de preț, trebuie mai întâi să selectați o perioadă de timp de bază - un interval de timp din trecut cu care se vor face comparații. Atunci când se alege un interval de timp de bază pentru un anumit indice, perioadele de stabilitate economică sunt favorizate față de perioadele de expansiune sau contracție economică. În plus, perioada de referință nu trebuie să fie prea îndepărtată în timp pentru ca rezultatele comparației să nu fie prea influențate de schimbările în tehnologie și obiceiurile consumatorilor. Indicele prețurilor se calculează folosind formula:

Unde eu i- indicele prețurilor în i an, Ri- preț în i an, P baza- pretul in anul de baza.
Indicele prețurilor este modificarea procentuală a prețului unui produs (sau al unui grup de produse) într-o anumită perioadă de timp în raport cu prețul produsului la un moment de bază. Ca exemplu, luați în considerare indicele prețurilor pentru benzina fără plumb în Statele Unite în perioada 1980-2002 (Fig. 24). De exemplu:


Orez. 24. Prețul benzinei fără plumb pe galon și indicele prețului simplu din SUA din 1980 până în 2002 (anii de bază 1980 și 1995)
Deci, în 2002 preţul benzinei fără plumb în SUA era cu 4,8% mai mare decât în 1980. Analiza Fig. 24 arată că indicele prețurilor în 1981 și 1982 a fost peste indicele prețurilor în 1980, iar apoi până în 2000 nu a depășit nivelul de bază. Deoarece 1980 este ales ca perioadă de bază, probabil că are sens să alegem un an mai apropiat, de exemplu, 1995. Formula de recalculare a indicelui în raport cu noua perioadă de timp de bază este:

Unde eunou- nou indice de preț, euvechi- indicele de preț vechi, eunou bază - valoarea indicelui prețurilor în noul an de bază atunci când este calculată pentru vechiul an de bază.
Să presupunem că 1995 este ales ca nouă bază. Folosind formula (10), obținem un nou indice de preț pentru 2002:
Deci, în 2002, benzina fără plumb în Statele Unite a costat cu 13,9% mai mult decât în 1995.
Indicii de preț compoziți neponderați. Deși un indice de preț pentru orice produs individual prezintă un interes indubitabil, mai important este un indice de preț pentru un grup de bunuri, care permite estimarea costului și a nivelului de trai al unui număr mare de consumatori. Indicele de preț compus neponderat, definit prin formula (11), atribuie o pondere egală fiecărui tip individual de produs. Un indice compozit al prețurilor reflectă modificarea procentuală a prețului unui grup de bunuri (numit adesea coș de piață) într-o anumită perioadă de timp în raport cu prețul acelui grup de bunuri la un moment de referință în timp.

Unde t i- numărul produsului (1, 2, …, n), n- numărul de bunuri din grupul în cauză, - suma prețurilor pentru fiecare dintre n bunuri într-o perioadă de timp t, - suma prețurilor pentru fiecare dintre n bunuri în perioada de timp zero, - valoarea indicelui compus neponderat în perioada de timp t.
În fig. 25 arată prețurile medii pentru trei tipuri de fructe pentru perioada 1980-1999. Pentru a calcula indicele compozit neponderat al prețurilor în diferiți ani, se utilizează formula (11), considerând 1980 ca an de bază.
Deci, în 1999, prețul total al unei lire de mere, al unei lire de banane și al unei lire de portocale a fost cu 59,4% mai mare decât prețul total al acestor fructe în 1980.

Orez. 25. Prețuri (în dolari) pentru trei tipuri de fructe și indice de preț compus neponderat
Un indice compozit al prețurilor neponderat exprimă modificările prețurilor unui întreg grup de bunuri în timp. Deși acest indice este ușor de calculat, are două dezavantaje evidente. În primul rând, atunci când se calculează acest indice, toate tipurile de bunuri sunt considerate la fel de importante, astfel încât mărfurile scumpe câștigă o influență nejustificată asupra indicelui. În al doilea rând, nu toate bunurile sunt consumate la fel de intens, astfel încât modificările prețurilor la bunurile mai puțin consumate afectează prea mult indicele neponderat.
Indicii de preț compoziți ponderați. Din cauza dezavantajelor indicilor de preț neponderați, sunt mai preferați indicii de preț ponderați care iau în considerare diferențele de preț și nivelurile de consum ale bunurilor care alcătuiesc coșul de consum. Există două tipuri de indici de preț compoziți ponderați. Indicele prețurilor Lapeyre, definit prin formula (12), utilizează nivelurile de consum din anul de bază. Un indice compozit ponderat al prețurilor ține cont de nivelurile de consum ale bunurilor care alcătuiesc coșul de consum, atribuind o anumită pondere fiecărui produs.

Unde t- perioada de timp (0, 1, 2, ...), i- numărul produsului (1, 2, …, n), n iîn perioada de timp zero, - valoarea indicelui Lapeyré în perioada de timp t.
Calculele indicelui Lapeyret sunt prezentate în Fig. 26; 1980 este folosit ca an de bază.

Orez. 26. Prețurile (în dolari), cantitatea (consumul în lire sterline pe cap de locuitor) a trei tipuri de fructe și indicele Lapeyret
Deci, indicele Lapeyret în 1999 este 154,2. Acest lucru indică faptul că în 1999 aceste trei tipuri de fructe erau cu 54,2% mai scumpe decât în 1980. Rețineți că acest indice este mai mic decât indicele neponderat de 159,4 deoarece prețul portocalelor, cel mai puțin consumat fruct, a crescut mai mult decât prețul la mere și banane. Cu alte cuvinte, deoarece prețurile celor mai consumate fructe au crescut mai puțin decât prețurile portocalelor, indicele Lapeyré este mai mic decât indicele compozit neponderat.
Indicele prețurilor Paasche folosește nivelurile de consum ale unui produs în perioada curentă, mai degrabă decât în perioada de timp de bază. În consecință, indicele Paasche reflectă mai exact costul total al consumului de bunuri la un moment dat în timp. Cu toate acestea, acest indice are două dezavantaje semnificative. În primul rând, nivelurile actuale de consum sunt în general dificil de determinat. Din acest motiv, mulți indici populari folosesc mai degrabă indicele Lapeyret decât indicele Paasche. În al doilea rând, dacă prețul unui anumit bun din coșul de consum crește brusc, cumpărătorii își reduc nivelul de consum din necesitate, și nu din cauza schimbărilor de gust. Indicele Paasche se calculează folosind formula:

Unde t- perioada de timp (0, 1, 2, ...), i- numărul produsului (1, 2, …, n), n- numărul de bunuri din grupul în cauză, - numărul de unități de mărfuri iîn perioada de timp zero, - valoarea indicelui Paasche în perioada de timp t.
Calculele indicelui Paasche sunt prezentate în Fig. 27; 1980 este folosit ca an de bază.

Orez. 27. Prețurile (în dolari), cantitatea (consumul în lire sterline pe cap de locuitor) a trei tipuri de fructe și indicele Paasche
Deci, indicele Paasche în 1999 este 147,0. Acest lucru indică faptul că în 1999 aceste trei tipuri de fructe erau cu 47,0% mai scumpe decât în 1980.
Unii indici de preț populari. Există mai mulți indici de preț utilizați în afaceri și economie. Cel mai popular este Indicele prețurilor de consum (IPC). Oficial, acest indice se numește IPC-U pentru a sublinia că este calculat pentru orașe (urban), deși, de regulă, se numește pur și simplu IPC. Acest index este publicat lunar de Biroul de Statistică a Muncii din SUA ca instrument principal pentru măsurarea costului vieții în Statele Unite. Indicele prețurilor de consum este compus și ponderat folosind metoda Lapeyret. Se calculează folosind prețurile celor mai consumate 400 de produse, tipuri de îmbrăcăminte, transport, servicii medicale și de utilități. În prezent, la calcularea acestui indice, perioada 1982–1984 este utilizată ca perioadă de bază. (Fig. 28). O funcție importantă a indicelui IPC este utilizarea sa ca deflator. Indicele IPC este utilizat pentru a converti prețurile reale în cele reale prin înmulțirea fiecărui preț cu un factor de 100/IPC. Calculele arată că în ultimii 30 de ani, rata medie anuală a inflației în Statele Unite a fost de 2,9%.

Orez. 28. Dinamica indicelui de consum al prețurilor; datele complete vezi fișierul excel
Un alt indice important al prețurilor publicat de Biroul de Statistică a Muncii este Indicele prețurilor de producător (PPI). IPP este un indice compozit ponderat care utilizează metoda Lapeyré pentru a măsura modificările prețurilor mărfurilor vândute de producătorii lor. Indicele PPI este indicatorul principal pentru indicele IPC. Cu alte cuvinte, o creștere a indicelui IPP duce la o creștere a indicelui IPC și invers, o scădere a indicelui IPP duce la o scădere a indicelui IPC. Indicii financiari precum Dow Jones Industrial Average (DJIA), S&P 500 și NASDAQ sunt utilizați pentru a măsura modificările prețurilor acțiunilor din Statele Unite. Mulți indici măsoară profitabilitatea piețelor internaționale de valori. Acești indici includ indicele Nikkei din Japonia, Dax 30 din Germania și SSE Composite din China.
Capcane asociate cu analiza timpului s x rânduri
Semnificația unei metodologii care folosește informații despre trecut și prezent pentru a prezice viitorul a fost descrisă cu elocvență în urmă cu mai bine de două sute de ani de omul de stat Patrick Henry: „Am o singură lampă pentru a lumina drumul - experiența mea. Numai cunoașterea trecutului permite cuiva să judeci viitorul.”
Analiza seriilor temporale se bazează pe presupunerea că factorii care au influențat activitatea afacerii în trecut și care influențează activitatea afacerii în prezent vor continua să funcționeze în viitor. Dacă acest lucru este adevărat, analiza seriilor temporale reprezintă un instrument eficient de prognoză și management. Cu toate acestea, criticii metodelor clasice bazate pe analiza seriilor de timp susțin că aceste metode sunt prea naive și primitive. Cu alte cuvinte, un model matematic care ia în considerare factorii care au funcționat în trecut nu ar trebui să extrapoleze mecanic tendințele în viitor fără a lua în considerare evaluările experților, experiența în afaceri, schimbările tehnologice, precum și obiceiurile și nevoile oamenilor. În încercarea de a corecta această situație, în ultimii ani econometricienii au dezvoltat modele computerizate sofisticate ale activității economice care țin cont de factorii enumerați mai sus.
Cu toate acestea, tehnicile de analiză a seriilor de timp sunt un instrument excelent de prognoză (atât pe termen scurt, cât și pe termen lung) atunci când sunt aplicate corect, în combinație cu alte tehnici de prognoză și cu judecata și experiența experților.
Rezumat.În această notă, utilizând analiza seriilor temporale, sunt dezvoltate modele pentru a prognoza veniturile a trei companii: Wm. Wrigley Jr. Companie, Cabot Corporation și Wal-Mart. Sunt descrise componentele unei serii de timp, precum și mai multe abordări de prognoză a seriilor temporale anuale - metoda mediei mobile, metoda de netezire exponențială, modele liniare, pătratice și exponențiale, precum și modelul autoregresiv. Este luat în considerare un model de regresie care conține variabile fictive corespunzătoare componentei sezoniere. Este prezentată aplicarea metodei celor mai mici pătrate pentru prognozarea seriilor temporale lunare și trimestriale (Fig. 29).
P grade de libertate se pierd la compararea valorilor seriilor temporale.
Analiza serii temporale vă permite să studiați performanța în timp. O serie temporală reprezintă valorile numerice ale unui indicator statistic, aranjate în ordine cronologică.
Astfel de date sunt comune într-o varietate de domenii ale activității umane: prețurile zilnice ale acțiunilor, cursurile de schimb, volumele de vânzări trimestriale, anuale, producția etc. O serie temporală tipică în meteorologie, cum ar fi precipitațiile lunare.
Dacă fixați valorile unui proces la anumite intervale, veți obține elementele seriei temporale. Ei încearcă să-și împartă variabilitatea în componente regulate și aleatorii. Schimbările regulate ale membrilor seriei sunt, de regulă, previzibile.
Să facem o analiză a seriilor temporale în Excel. Exemplu: un lanț de retail analizează datele vânzărilor de la magazinele situate în orașe cu o populație mai mică de 50.000 de persoane. Perioada - 2012-2015 Sarcina este de a identifica tendința principală de dezvoltare.
Să introducem datele vânzărilor într-un tabel Excel:
În fila „Date”, faceți clic pe butonul „Analiza datelor”. Dacă nu este vizibil, mergeți la meniu. „Opțiuni Excel” - „Suplimente”. În partea de jos, faceți clic pe „Mergeți” la „Suplimente Excel” și selectați „Pachet de analiză”.
Conectarea setării „Analiza datelor” este descrisă în detaliu.
Butonul necesar va apărea pe panglică.

Din lista propusă de instrumente pentru analiză statistică, selectați „Netezire exponențială”. Această metodă de egalizare este potrivită pentru seriile noastre cronologice, ale căror valori fluctuează foarte mult.
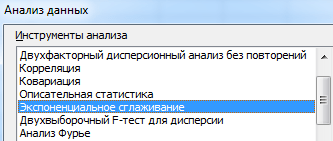
Completați caseta de dialog. Interval de intrare – un interval cu valorile vânzărilor. Factorul de degradare - factor de netezire exponențial (implicit - 0,3). Interval de ieșire – referință la celula din stânga sus a intervalului de ieșire. Programul va plasa nivelurile netezite aici și va determina dimensiunea în mod independent. Bifați casetele „Ieșire grafică”, „Erori standard”.
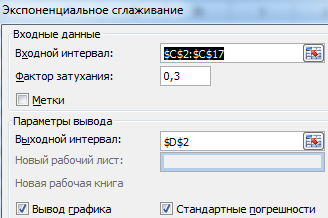
Închideți caseta de dialog făcând clic pe OK. Rezultatele analizei:

Pentru a calcula erorile standard, Excel folosește formula: =SQRT(SUMQDIFF('interval de valori reale'; 'interval de valori estimate')/'netezirea dimensiunii ferestrei'). De exemplu, =ROOT(SUMVARE(C3:C5;D3:D5)/3).
Să facem o prognoză de vânzări folosind datele din exemplul anterior.
Să adăugăm o linie de tendință la grafic care afișează volumele reale de vânzări de produse (butonul din dreapta al graficului este „Adăugați linia de tendință”).
Configurarea parametrilor liniei de tendință:

Alegem o tendință polinomială, care minimizează pe cât posibil eroarea modelului predictiv.

R2 = 0,9567, ceea ce înseamnă că acest raport explică 95,67% din modificarea vânzărilor în timp.
O ecuație de tendință este o formulă de model pentru calcularea valorilor prognozate.
Obținem un rezultat destul de optimist:

În exemplul nostru, există încă o dependență exponențială. Prin urmare, atunci când se construiește o tendință liniară, există mai multe erori și inexactități.
De asemenea, puteți utiliza funcția GROWTH pentru a prezice o relație exponențială în Excel.

Pentru o relație liniară – TREND.
Când faceți prognoze, nu puteți utiliza o singură metodă: există o probabilitate mare de abateri mari și inexactități.
07.10.2013 Tyler Chessman
Înțelegerea ideilor cheie din spatele prognozei serii de timp și familiarizarea cu unele dintre detalii vă va oferi un avantaj în utilizarea capabilităților de prognoză ale SQL Server Analysis Services (SSAS)
Acest articol va descrie conceptele de bază necesare pentru a stăpâni tehnologiile de data mining. Vom acoperi, de asemenea, câteva dintre punctele mai fine, astfel încât, atunci când le întâlniți în practică, să nu vă descurajați (consultați bara laterală „De ce miningul de date este atât de nepopular”).
Din când în când, profesioniștii SQL Server trebuie să facă estimări anticipative ale valorii viitoare, cum ar fi prognozele privind veniturile sau vânzările. Organizațiile folosesc uneori tehnologia de extragere a datelor pentru a construi modele predictive pentru a furniza astfel de estimări. Odată ce înțelegeți conceptele de bază și unele detalii, veți fi pe cale de a utiliza capabilitățile de prognoză ale SQL Server Analysis Services (SSAS).
Există diverse abordări ale prognozei. De exemplu, site-ul web Forecasting Methods (forecastingmethods.org) identifică diferite categorii de metode de prognoză, inclusiv casual (cunoscute și sub numele de economie), modelare expertă (subiectivă), serii cronologice, inteligență artificială, previziuni de piață, prognoză probabilistică, modelare de prognoză și prognoza bazata pe clase de referinta. Site-ul web Forecasting Principles (www.forecastingprinciples.com) oferă o privire de ansamblu asupra metodelor sub forma unui arbore metodologic, în primul rând distingând între metodele subiective (adică metodele utilizate atunci când există date insuficiente disponibile pentru analiza cantitativă) și metodele statice (care este, metodele utilizate atunci când sunt disponibile date numerice corespunzătoare). În acest articol, mă voi concentra pe prognoza în serie de timp, un tip de abordare statică în care datele acumulate sunt suficiente pentru a prezice performanța.
Prognoza serii temporale presupune că datele obținute în trecut ajută la explicarea valorilor în viitor. Este important să înțelegem că în unele cazuri avem de-a face cu detalii care nu se reflectă în datele acumulate. De exemplu, va apărea un nou concurent care ar putea afecta negativ veniturile viitoare sau schimbări rapide în compoziția forței de muncă care ar putea afecta ratele șomajului. În astfel de situații, prognoza serii temporale nu poate fi singura abordare. Adesea, diferite abordări de prognoză sunt combinate pentru a oferi cele mai precise prognoze.
O serie temporală este o colecție de valori obținute pe o perioadă de timp, de obicei la intervale regulate. Exemplele comune includ vânzările săptămânale, cheltuielile trimestriale și ratele lunare ale șomajului. Datele din seria temporală sunt prezentate într-un format grafic, cu interval de timp de-a lungul axei x a graficului și valorile de-a lungul axei y, așa cum arată figura 1.
Când luați în considerare modul în care o valoare se schimbă de la o perioadă la alta și cum să preziceți valorile, rețineți că datele din seria temporală au câteva caracteristici importante.
Deci, prin identificarea tendinței, suprapunerea liniei de tendință pe linia de bază și identificarea componentei sezoniere care poate fi prezentă în analiza datelor, aveți un model predictiv care poate fi utilizat pentru a prezice valori:
Valoarea estimată = Linia de bază + Tendință + componentă sezonieră
Singura modalitate de a determina valoarea de bază și tendința este utilizarea metodei regresiei. Cuvântul „regresie” se referă aici la luarea în considerare a relației dintre variabile. În acest caz, există o relație între variabila timp independentă și variabila dependentă a numărului de șomeri. Rețineți că variabila independentă este uneori numită predictor.
Utilizați un instrument precum Microsoft Excel pentru a aplica metoda de regresie. De exemplu, puteți efectua un calcul automat în Excel și puteți adăuga o linie de tendință la o diagramă de serie temporală utilizând meniul Linie de tendință din fila Aspect instrumente diagramă sau fila Aspect instrumente diagramă pivot din panoul Excel 2010 sau Excel 2007. În Figura 1, I a adăugat o linie de tendință dreaptă selectând Mode Linear trendline din meniul Trendline. Apoi am selectat Mai multe opțiuni de linie de tendință din meniul Linie de tendință, apoi opțiunile Afișare ecuație pe diagramă și Afișare valoare R-pătrat pe diagramă, vezi Figura 3.
.jpg) |
| Ecranul 3: Opțiuni de tendință în Excel |
Acest proces de ajustare a unei linii de tendință la datele acumulate se numește regresie liniară. După cum putem vedea în ecranul 1, linia de tendință este calculată în funcție de ecuația în care sunt determinate nivelul de bază (8248.8) și tendința (104.67x):
y = 104,67x + 8248,8
Vă puteți gândi la o linie de tendință ca o serie de coordonate x-y legate în care puteți conecta un interval de timp (adică axa x) pentru a obține o valoare (axa y). Excel determină „cea mai bună” linie de tendință folosind metoda celor mai mici pătrate (definită ca R² în Figura 1). O linie cu cele mai mici pătrate este o linie care minimizează distanța verticală pătrată de la fiecare punct de pe o linie de tendință până la punctul corespunzător de pe linie. Valorile RMS vă permit să determinați că abaterile deasupra sau sub linia reală nu se echilibrează reciproc. În ecranul 1, vedem că R² = 0,5039, ceea ce înseamnă că relația liniară explică 50,39% din modificările statisticilor șomajului de-a lungul timpului.
Determinarea unei linii de tendință precisă în Excel implică adesea încercări și erori, împreună cu inspecția vizuală. În ecranul 1, o linie dreaptă de tendință nu se potrivește bine. Excel oferă alte opțiuni pentru linia de tendință, pe care le vedeți în Figura 3. În Figura 4, am adăugat o linie medie mobilă cu patru perioade, care se bazează pe media aritmetică a perioadei curente și a ultimei perioade stabilite din seria temporală.
De asemenea, am adăugat o linie de tendință polinomială prin aplicarea unei ecuații algebrice pentru a trasa linia. Rețineți că linia de tendință polinomială are o valoare R² de 0,9318, care determină cel mai bun raport în exprimarea relației dintre variabilele independente și dependente. Cu toate acestea, un R² mai mare nu înseamnă neapărat că linia de tendință va oferi valoare predictivă. Există și alte metode de calculare a prognozelor precise, pe care le voi descrie pe scurt mai jos. Unele opțiuni ale liniilor de tendință din Excel (de exemplu, linii de tendință liniare, polinomiale) vă permit să faceți prognoze înainte și înapoi, ținând cont de numărul de perioade, trasând valorile rezultate pe un grafic. Expresia „prognoză în direcția opusă” poate părea ciudată pentru unii. Cel mai bun mod de a ilustra acest lucru este cu un exemplu. Să presupunem că un nou factor - o creștere rapidă a locurilor de muncă din sectorul public (de exemplu, locuri de muncă în Homeland Defense la începutul anilor 2000, lucrători temporari ai Biroului de Recensământ al SUA) - a provocat o scădere rapidă a ratei șomajului. Trebuie să proiectați rata de creștere a noului sector de locuri de muncă înapoi pe parcursul mai multor luni și apoi să recalculați rata șomajului pentru a ajunge la o rată de schimbare uniformă.
De asemenea, puteți aplica manual ecuația liniei de tendință pentru a calcula valori pentru viitor. În Figura 5, am adăugat o linie de tendință polinomială cu o prognoză pe 6 luni, eliminând mai întâi ultimele 6 luni de date (adică, din aprilie până în septembrie 2012) din seria temporală inițială.
Dacă comparați Ecranul 5 cu Ecranul 1, veți observa că prognozele polinomiale au o tendință ascendentă, care nu corespunde trendului descendent al seriei temporale reale.
Există două puncte importante de făcut despre regresie.
Componenta sezonieră în structura unei serii temporale apare de obicei în legătură fie cu ziua săptămânii, fie cu ziua lunii, fie cu luna anului. După cum sa menționat mai sus, numărul șomerilor din Statele Unite ale Americii crește și scade de obicei într-un anumit an calendaristic. Acest lucru este valabil chiar și atunci când economia este în creștere, așa cum se arată în Figura 2. Cu alte cuvinte, pentru a face o prognoză precisă, trebuie să țineți cont de sezonalitate. O abordare comună este aplicarea unei metode de netezire sezonieră. În Practical Time Series Forecasting: A Hands-On Guide, Second Edition (CreateSpace Independent Publishing Platform, 2012), autorul Galit Shmueli recomandă utilizarea uneia dintre cele trei metode:
Nivelul de bază și tendința sunt determinate la calcularea prognozei ținând cont de seria temporală netezită. Opțional, o componentă sau o ajustare sezonieră poate fi reaplicată la valorile prognozate, ținând cont de valorile inițiale ale factorului sezonier atunci când se lucrează cu metoda Holt-Winters. Dacă doriți să vedeți cum se calculează sezonalitatea în Excel, căutați online „Metoda Winters în Excel”. De asemenea, o explicație detaliată a metodei Holt-Winters poate fi găsită în Wayne L. Winston Microsoft Office Excel 2007: Data Analysis and Business Modeling, Second Edition (Microsoft Press, 2007).
Multe pachete de data mining, cum ar fi SSAS, iau automat în considerare sezonalitatea în algoritmii de prognoză a seriilor de timp, măsurând modelele sezoniere și încorporându-le în modelul de prognoză. Cu toate acestea, poate doriți să oferiți indicii despre modelul schimbărilor sezoniere.
După cum sa menționat deja, modelul original (dacă se utilizează metoda celor mai mici pătrate) nu oferă neapărat predicții precise. Cel mai bun mod de a testa acuratețea estimărilor de prognoză este împărțirea seriei temporale în două seturi de date: unul pentru construirea (adică antrenamentul) modelului și altul pentru validare. Setul de date de validare va fi cea mai recentă parte a setului de date original și, în mod ideal, se întinde pe scara de timp a prognozei viitoare. Pentru a verifica (valida) modelul, valorile prezise sunt comparate cu valorile reale. Rețineți că, odată ce ați validat, modelul poate fi reconstruit utilizând întreaga serie de timp, așa că este recomandabil să folosiți cele mai recente valori reale pentru a prezice valorile viitoare ale metricii.
Când se măsoară acuratețea unui model de prognoză, apar în mod obișnuit două întrebări: cum se determină acuratețea estimării prognozei și câte date istorice trebuie utilizate pentru a antrena modelul.
Cum se determină acuratețea unei estimări de prognoză? În unele scenarii, valorile proiectate mai mari decât valorile reale pot fi nedorite (de exemplu, în previziunile privind activitatea investițională). În alte situații, valorile estimate mai mici decât valorile reale pot avea consecințe devastatoare (de exemplu, estimarea celui mai mic preț câștigător pentru un articol de licitație). Dar în cazurile în care doriți să calculați un scor pentru toate prognozele (indiferent dacă valorile prognozate sunt mai mari sau mai mici decât valorile reale), puteți începe cu eroarea cantitativă dintr-o prognoză individuală folosind definiția:
eroare = valoare estimată – valoare reală
Cu această definiție a erorii, există două metode populare de măsurare a preciziei: eroarea medie absolută (MAE) și eroarea procentuală medie absolută (MAPE). În metoda MAE, valorile absolute ale erorilor de prognoză sunt însumate și apoi împărțite la numărul total de prognoze. Metoda MAPE calculează abaterea medie absolută de la prognoză în procente. Pentru a vedea exemple de aceste și alte metode de măsurare a calității estimărilor de prognoză, vizitați Șablonul de Diagnosticare pentru valorile cererii (demandplanning.net/DemandMetricsExcelTemp.htm) șablon Excel (cu date de prognoză eșantion și rate de precizie).
Câte date istorice ar trebui folosite pentru a antrena modelul? Când lucrați cu o serie temporală care are o istorie lungă, este posibil să doriți să includeți toate datele istorice în model. Cu toate acestea, uneori, istoricul suplimentar nu îmbunătățește acuratețea prognozei. Datele istorice pot chiar distorsiona prognoza dacă condițiile trecute diferă semnificativ de cele din prezent (de exemplu, compoziția forței de muncă în prezent și în trecut este diferită). Nu am întâlnit nicio formulă specială sau metodă practică care să sugereze câte date istorice să includă, așa că sugerez să începeți cu serii de timp care sunt de câteva ori mai mari decât intervalele de timp prognozate și apoi să verificați acuratețea. Apoi, încercați să rotunjiți numărul istoric în sus sau în jos și testați din nou.
Prognoza serii temporale a apărut pentru prima dată în SSAS în 2005. Pentru a calcula valorile de prognoză, algoritmul Microsoft Time Series a folosit un singur algoritm numit arbore autoregresiv cu predicție încrucișată (ARTXP) sau un arbore autoregresiv cu predicție încrucișată. ARTXP combină autoregresiunea cu extragerea datelor din arborele de decizie, astfel încât ecuația de prognoză să se poată modifica (adică împărțirea) pe baza anumitor criterii. De exemplu, un model de prognoză va oferi o potrivire mai bună (și o precizie mai mare a prognozei) dacă mai întâi se împarte după dată și apoi se împarte pe baza valorii variabilei independente, așa cum arată Figura 6.
.jpg) |
| Figura 6: Exemplu de arbore de decizie ARTXP în SSAS |
În SSAS 2008, algoritmul Microsoft Time Series a început să utilizeze un algoritm numit mediu mobil integrat autoregresiv (ARIMA), pe lângă ARTXP, pentru a calcula prognozele pe termen lung. ARIMA este considerat un standard industrial și poate fi gândit ca o combinație de procese autoregresive și modele de medie mobilă. În plus, analizează erorile istorice de prognoză pentru a îmbunătăți modelul.
În mod implicit, algoritmul Microsoft Time Series combină rezultatele algoritmilor ARIMA și ARTXP pentru a obține predicții optime. Puteți anula această funcție dacă doriți. Să ne uităm la documentația SQL Server Books Online (BOL):
„Algoritmul antrenează două modele diferite ale acelorași date: un model folosește algoritmul ARTXP, iar celălalt folosește algoritmul ARIMA. Algoritmul combină apoi rezultatele celor două modele pentru a dezvolta cea mai bună prognoză care acoperă un număr variabil de secțiuni de timp. Deoarece algoritmul ARTXP este mai potrivit pentru prognozele pe termen scurt, este recomandabil să îl utilizați la începutul unei serii de prognoze. Cu toate acestea, dacă intervalele de timp necesare pentru prognoză merg în viitor, algoritmul ARIMA este mai semnificativ.”
Când lucrați cu prognoza serii cronologice în SSAS, ar trebui să aveți în vedere întotdeauna următoarele:
În acest articol, v-am prezentat elementele de bază ale prognozării serii cronologice. De asemenea, am acoperit câteva detalii ale algoritmilor de bază, astfel încât aceștia să nu devină un obstacol în calea procesării seriilor temporale. Ca pas următor, vă sugerez să stăpâniți instrumentele de prognoză a seriilor temporale cu SSAS. Un exemplu ar fi un proiect care folosește datele despre șomaj prezentate în acest articol. Apoi puteți consulta tutorialul online TechNet, Tutorial Intermediate Data Mining (Analysis Services - Data Mining) la technet.microsoft.com/en-us/library /cc879271.aspx.
În ultimul deceniu, tehnologiile de business intelligence (BI), precum OLAP, au devenit utilizate pe scară largă. În același timp, Microsoft a început să promoveze o altă tehnologie BI, data mining, în instrumente atât de populare precum Microsoft SQL Server și Microsoft Excel. Cu toate acestea, tehnologia data mining nu a devenit încă o tehnologie de vârf. De ce? Deși majoritatea oamenilor pot înțelege rapid esența conceptelor cheie ale minării de date, detaliile de bază ale algoritmilor sunt indisolubil legate de concepte și formule matematice. Există o mare „discrepanță” între nivelurile înalte de înțelegere abstractă și execuția detaliată. Ca rezultat, data mining-ul este privit ca o „cutie neagră” de către profesioniștii IT și clienții industriali, ceea ce nu este favorabil adoptării pe scară largă a tehnologiei. Acest articol este încercarea mea de a reduce „divergența” în prognoza seriilor temporale.
În articolul principal, datele pentru grafice se bazează pe informații despre populația activă publicate de U.S. Biroul de Statistică a Muncii (http://www.bls.gov/). BLS publică ratele șomajului pe baza unui sondaj lunar realizat de Biroul de Recensământ al SUA (BLS) care extrapolează numărul total de oameni angajați și șomeri. Mai exact, BLS folosește formula:
Rata șomajului = șomer/(șomer + angajat)
Este de remarcat faptul că, când vine vorba de rata șomajului, mass-media citează de obicei o rată ajustată sezonier. Ajustarea sezonieră se realizează folosind un model general numit medie mobilă integrată autoregresivă (ARIMA). Acesta este, în esență, același algoritm care este utilizat în multe pachete de data mining pentru prognoza serii temporale, inclusiv SQL Server Analysis Services (SSAS). Pentru mai multe informații despre modelul ARIMA utilizat de BLS, vizitați pagina web a Programului de ajustare sezonieră X-12-ARIMA (www.census.gov/srd/www/x12a/). Vă rugăm să rețineți că în exemplul de proiect pentru acest articol, am folosit valori ajustate sezonier și non-sezon.









