
Živjo.
Želim govoriti o enem problemu, ki me je naenkrat zelo zanimal, in sicer o problemu napovedovanja časovnih vrst in reševanju tega problema z metodo algoritma mravelj.
Za začetek na kratko o problemu in samem algoritmu:
Napovedovanje časovnih vrst pomeni, da je vrednost določene funkcije znana v prvih n točkah časovne vrste. Z uporabo teh informacij je treba predvideti vrednost pri n + 1 točki v časovnem nizu. Obstaja veliko različnih načinov napovedovanja, danes pa sta metoda Winters in model ARIMA med najpogostejšimi. Več o njih si lahko preberete.
O tem, kaj je mravlji algoritem, je bilo že veliko povedanega. Za tiste, ki so leni za plezanje, na primer tukaj, Bom pripovedoval. Skratka, kolonija mravelj je simulacija obnašanja kolonije mravelj v njihovem prizadevanju najti najkrajšo pot do vira hrane. Mravlje pri premikanju puščajo sledi feromona, kar vpliva na verjetnost, da bo mravlja izbrala določeno pot. Glede na to, da bodo mravlje v istem časovnem obdobju večkrat prešle kratko pot, bo na njej ostalo več feromonov. Tako bo sčasoma več mravelj ubralo najkrajšo pot do vira hrane.
Zaradi jasnosti bom vstavil sliko:
Zdaj pa pojdimo neposredno k reševanju problema napovedovanja z uporabo metode kolonije mravlje.
Prva težava, s katero se srečujemo, je, da je treba časovno vrsto predstaviti v obliki grafa, na katerem bomo zagnali algoritem mravelj.
Najdeni sta bili dve možni rešitvi:
1. Predstavite časovno vrsto v obliki več grafa, kjer se lahko od vsake točke časovne vrste pomaknete do vsake z nizom določenih korakov. (Za lažjo nalogo bomo vzeli normalizirane vrednosti v razponu od -1 do 1). To je bil prvi pristop, ki smo ga poskusili. Pri nizkodimenzionalnih časovnih vrstah je pokazal dober rezultat, a s povečanjem dimenzije sta se natančnost napovedi in uspešnost močno začeli zniževati, zato je bila ta možnost opuščena.
2. Predstaviti časovno vrsto v obliki niza povezanih grafov, pri čemer je vsak graf odgovoren za lastno povečanje vrednosti časovne vrste. z drugimi besedami, imamo graf, ki je odgovoren za povečanje -1, -0,9 ... in tako naprej do 1. Korak je seveda mogoče zmanjšati ali povečati, kar bo vplivalo na natančnost napovedi in vir intenzivnost problema. (Na koncu se je ta možnost izkazala za najuspešnejšo.)
Na tem nizu povezanih grafov je bil sprožen algoritem mravelj (na vsakem grafu lasten), ki je odložil feromon na robove, ki ustrezajo znanim vrednostim časovne vrste. Poleg tega, ko je bil feromon odložen na stolpec i, je bil feromon odložen tudi na stolpca i-1 in i + 1, vendar v precej manjši količini (v našem primeru 1/10 osnovne količine feromona). in zaradi odlaganja feromona na sosednjih stolpcih je bila možna napaka in začetna hrupnost časovne vrste izravnana.
Ta algoritem smo preizkusili na umetno pripravljenih časovnih vrstah z različnimi stopnjami frekvence in šuma. Rezultat je dvojen. Po eni strani pri ravni hrupa do 0,3 algoritem prikazuje visoke napovedne rezultate, primerljive z rezultati modela ARIMA. Pri višjih ravneh hrupa je razpršenost rezultatov velika: napoved je zelo natančna, včasih popolnoma napačna.
Trenutno delamo na izbiri optimalne vrednosti parametrov algoritma in nekaterih metodah za njegovo izboljšanje, o čemer bom pisal takoj, ko bodo dovolj preverjeni.
Hvala vsem za pozornost.
Posodobljeno: Poskušal bom odgovoriti na vaša vprašanja.
Multigraf je graf, katerega vsak vrh je povezan z vsakim.
Kaotične serije, kot je že omenjeno spodaj, niso naključne. Ogledate si lahko slike serije Lorentz v tridimenzionalnem prostoru in si ogledate ciklično gibanje. To cikličnost je preprosto težko določiti in na prvi pogled je serija videti naključna.
Vrednosti časovnih vrst se normalizirajo v intervalu -1 ... 1 in zapišejo v graf. Graf - v tem primeru tabela prehodov iz teme v točko. Feromon se odlaga na robovih (v celicah mize).
V primeru verižnih grafov se uporablja več tabel, od katerih je vsaka odgovorna le za svojo velikost prehoda.
Odvisno od količine feromona v določeni celici se kot rezultat napovedi izbere ena ali druga vrednost časovne vrste.
Algoritem je bil preizkušen predvsem na seriji Lorentz.
Trenutno je še prezgodaj govoriti, koliko je bolje ali slabše. Zdi se, da je algoritem dovzeten za iskanje psevdoobdobja in z naraščanjem ravni hrupa se število lažnih obdobij povečuje.
Po drugi strani pa je pri uspešnem izboru parametrov natančnost napovedi precej visoka (odstopanje je do 7-10 odstotkov, kar ni slabo za kaotično serijo.)
Kasneje bomo prešli na testiranje resničnih podatkov. V bližnji prihodnosti bom poskušal pripraviti in dodati slike.
Hvala za pozornost.
Analiza časovnih vrst (ATS) je najpreprostejša metoda za obnovitev odvisnosti v determinističnem primeru, ki temelji na dani časovni vrsti. Glavna naloga je ekstrapolacija (napoved) - najlažji način napovedovanja razmer na trgu. Njegovo bistvo je širjenje trendov, ki so se razvijali v preteklosti in prihodnosti.
Številni tržni procesi so inertni, kar se upošteva pri oblikovanju napovedi. Za določeno obdobje je treba čim bolj upoštevati verjetnost sprememb tržnih razmer. Predpostavlja se, da se sistem razvija v dokaj stabilnih pogojih. Večji kot je sistem, večja je verjetnost, da bodo parametri nespremenjeni, vendar ne dolgo časa. Priporočljivo je, da napovedano obdobje ne presega 1/3 trajanja prvotne časovne osnove.
Časovna vrsta je vrsta številskih vrednosti, dobljenih v rednih časovnih presledkih. Glavno načelo, na katerem temelji uporaba časovnih vrst v podjetju, je, da dejavniki, ki vplivajo na odziv preučevalnega sistema, ki delujejo v preteklosti, sedanjosti in podobno bo delovalo v bližnji prihodnosti.
Namen analize je oceniti in izolirati dejavnike, da bi predvideli nadaljnje obnašanje sistema in razvili racionalno SD. Napoved na podlagi ATS je kratkoročna, glede na obdobje, za katero je sprejeta, se značilnosti obravnavanega pojava ne spreminjajo bistveno. Večina napak pri napovedi je posledica dejstva, da napoved predvideva ohranitev preteklih trendov v prihodnosti. Ta hipoteza je v gospodarskem in družbenem življenju redko upravičena.
VR lahko postane slaba podlaga za razvoj napovedi, zato se metode napovedovanja in ATS uporabljajo za kratkoročno napovedovanje dokaj stabilnih in dobro preučenih procesov. Napovedano obdobje ne presega 25-30% prvotne časovne osnove. Pri uporabi regresijske enačbe se izvedejo napovedni izračuni za optimistične in pesimistične ocene začetnih parametrov. Od tu dobimo dve vrsti napovedi: optimistično in pesimistično. Ocena napovedi, pridobljena na podlagi metod napovedovanja, se uporablja kot pokazatelj želene vrednosti parametra napovedi.
BP vključuje:
1) trend - prikazuje splošno vrsto sprememb, dolgoročno zmanjšanje in povečanje serije,
2) sezonska nihanja - nihanja okoli trenda, ki se pojavljajo redno.
Običajno se v obdobju do enega leta pojavljajo redna nihanja. Lahko jih spremljamo četrtletno, mesečno, tedensko itd. opazovanja.
3) ciklična nihanja - pojavljajo se v obdobjih, daljših od enega leta. Pogosto so prisotni v finančnih podatkih in so povezani z močnim upadom, hitro rastjo in obdobjem stagnacije.
4) naključna nihanja - nepredvidljiva nihanja v večini resničnih VR.
Zahteve po podatkih za časovno vrsto
Vse metode napovedovanja uporabljajo matematično statistiko, zato je potrebno, da so vsi podatki primerljivi, dovolj zastopani za manifestacijo homogenosti in stabilnosti. Zaradi neizpolnjevanja ene od teh zahtev je uporaba matematične statistike nesmiselna.
1. Primerljivost je dosežen kot rezultat istega pristopa k opazovanjem na različnih stopnjah oblikovanja časovne vrste. Podatki v časovnih vrstah morajo biti izraženi v istih merskih enotah, imeti isti korak opazovanja, izračunati za isti časovni interval z isto metodologijo, zajeti iste elemente, ki pripadajo istemu ozemlju in se nanašajo na nespremenjeno populacijo.
Neprimerljivost podatkov se najpogosteje kaže v kazalnikih stroškov. Tudi v primerih, ko so vrednosti teh kazalnikov fiksne po stalnih cenah. Tovrstne neprimerljivosti časovnih vrst ni mogoče odpraviti s čisto formalnimi metodami.
2. Reprezentativnost podatkov za katerega je značilna predvsem popolnost predstavljenih podatkov. Zadostno število opazovanj se določi glede na namen izvedene študije. Če je cilj opisna statistična analiza, lahko za preučeni časovni interval izberete poljuben interval. Če je cilj študije zgraditi model napovedovanja, mora biti število podatkov v začetni časovni vrsti vsaj 3 -kratnik napovedanega obdobja in ne sme biti manjši od 7 podatkov. V primeru uporabe četrtletnih ali mesečnih podatkov za preučevanje sezonskosti in napovedovanje sezonskih procesov mora začetna časovna vrsta vsebovati četrtletne ali mesečne podatke za najmanj 4 leta, tudi če je napoved potrebna za 1 ali 2 meseca.
3.Enotnost- odsotnost netipičnih nepravilnih opazovanj, pa tudi prekinitve trendov (sprememba). Nepravilnost vodi do pristranskosti v ocenah in posledično do popačenja rezultatov analize. Formalno se nenormalnost pojavi kot močan skok ali upad, ki mu sledi približno okrevanje prejšnje ravni. Za diagnozo nenormalnih opazovanj so bila razvita različna standardna merila.
4. Trajnost- ta lastnost odraža prevlado pravilnosti nad naključnostjo v spremembah ravni in niza. Na grafih stabilnih časovnih vrst lahko vzorec zasledimo celo vizualno. Na lestvicah nestabilnih časovnih vrst so spremembe predstavljene kaotično. Zato v takšnih časovnih vrstah ni smiselno iskati vzorcev.
Modeli časovnih vrst
Metode statističnih raziskav temeljijo na predpostavki možnosti predstavitve vrednosti časovnih vrst v obliki kombinacije več komponent, ki odražajo pravilnost in naključnost razvoja. Zlasti za kratkoročne napovedi se uporabljajo aditivni (adaptivni) in multiplikativni modeli.
1. Prilagodljiv (dodatek)
Y (t) = T (t) + S (t) + F (t)
t - številka časovnega intervala
T (t) - razvojni trend (dolgoročni trend)
S (t) - sezonska komponenta
E (t) - preostala komponenta
2. Multiplikativno
Y (t) = T (t) * S (t) * F (t)
Pri konstantnosti ene jakosti sezonske amplitude valov je priporočljivo uporabiti aditivni model. Ko se amplituda sezonskega vala spremeni v skladu s trendom povprečne ravni, se uporabi multiplikativni model. Včasih se uporabljajo modeli mešanega tipa, ki dajejo natančnejši rezultat, vendar so vsebinsko slabo interpretirani. Uporaba multiplikativnega modela je posledica dejstva, da je v nekaterih časovnih vrstah vrednost sezonske komponente določen del vrednosti trenda. Praksa kaže, da kadar sezonska nihanja obravnavanega procesa velika in niso zelo stabilna, daje multiplikativni model slabe rezultate. Sezonska komponenta označuje stabilna in medletna nihanja ravni - kaže se v nekaterih kazalnikih, predstavljenih s četrtletnimi ali mesečnimi podatki.
Pri modelih z aditivno in multiplikativno komponento je splošni postopek analize približno enak.
Morate narediti:
1) izračun vrednosti sezonske komponente
2) od dejanskih vrednosti odštejemo sezonsko komponento- ta proces se imenuje desezonizacija (odprava sezonskosti)
3) izračun napak kot razlike med dejanskimi in trendnimi vrednostmi
4) izračun srednjega odstopanja ali kvadratne napake
Tudi napovedovanje uporablja modeli krivulj rasti.
Krivulje rasti so matematične funkcije, namenjene analitičnemu poravnavanju časovne vrste.
Za opis krivulj rasti se uporabljajo naslednje funkcije
2. Parabola Y (t) = a + bt = ct 2
3. Hiperbola Y (t) = a + b / t
4. Moč
5. Ilustrativno
6. Logaritemska
7. Johnsonova krivulja
8. Spremenjen razstavljavec
Zglajevanje časovnih vrst
Razkritje glavnega razvojnega trenda se imenuje poravnava ali glajenje časovnega niza. Metode za prepoznavanje glavnega trenda so metode usklajevanja.
Ena najpreprostejših metod odkrivanja splošnega trenda v razvoju pojava je povečanje intervala časovnih vrst. Za prepoznavanje razvojnih trendov se uporablja metoda drsečega povprečja ali metoda eksponentnega glajenja. Obe metodi sta subjektivni glede izbire parametrov izravnave. In prav pri pravilni izbiri parametrov se kaže intuicija raziskovalca.
Metoda drsečega povprečja- je zelo subjektivno in na rezultate glajenja močno vpliva dolžina obdobja glajenja. S kratkimi obdobji ni mogoče prepoznati komponente trenda. Dolga obdobja se na koncu analiziranega intervala pojavi znatna izguba podatkov.
Drseče povprečje reda L je časovna vrsta, sestavljena iz aritmetične sredine in aritmetične sredine L v sosednjih vrednostih funkcije Y za vse možne časovne vrednosti. Kot L-liho število, 3, 5,7-tri, pet in sedem točk.
Shema v treh točkah: povprečna vrednost bo izračunana na podlagi vrednosti 3 Yi, od katerih se ena nanaša na prejšnje obdobje, druga na želeno in 3 na prihodnje obdobje. Če je i = 1, ni pretekle vrednosti, potem zglajene vrednosti ni mogoče izračunati na prvi točki. Če je i = 2, bo povprečje aritmetična sredina.
Na zadnji točki začetnega intervala ni mogoče izračunati drsečega povprečja tudi zaradi odsotnosti prihodnje vrednosti glede na izračunano.
Metoda eksponentnega glajenja- v nasprotju z drsečim povprečjem se lahko uporabi za kratkoročne napovedi v prihodnjem trendu za eno prihodnje obdobje. Zato ima metoda očitno prednost pred prejšnjo.
Algoritem za izračun zglajenih vrednosti na kateri koli točki v nizu temelji na treh vrednostih: opazovani vrednosti Yi na dani točki, izračunani zglajeni vrednosti za prejšnjo točko serije in nekaterih vnaprej določenih koeficientih glajenja, ki so konstantni serija.
Fi = α * Yi + (α-1) * Fi
Yi je dejanska vrednost skupne točke serije.
Zglajena vrednost za prejšnjo točko v nizu je (alfa-1)
Alfa ima lahko poljubno vrednost od 0 do 1, vendar je v praksi običajno omejena na območje od 0,2 do 0,5
Holtova metoda. L t = k * Y t + (1-k) * (L t-1 -T t-1), kjer
L t - zglajena vrednost za tekoče obdobje;
K je faktor glajenja vrstice;
Y t - trenutna vrednost serije (na primer obseg prodaje);
L t -1 - zglajena vrednost za prejšnje obdobje;
T t -1 - vrednost trenda za prejšnje obdobje.
Tri prejšnje opombe opisujejo regresijske modele, ki napovedujejo odziv iz vrednosti pojasnjevalnih spremenljivk. V tem prispevku vam pokažemo, kako uporabiti te modele in druge statistične tehnike za analizo podatkov, zbranih v zaporednih časovnih intervalih. Na podlagi posebnosti vsakega podjetja, omenjenega v scenariju, bomo razmislili o treh alternativnih pristopih k analizi časovnih vrst.
Material bo ponazorjen s presečnim primerom: napoved prihodkov treh podjetij... Predstavljajte si, da ste analitik velikega finančnega podjetja. Za oceno naložbenih možnosti vaših strank morate napovedati zaslužek treh podjetij. V ta namen ste zbrali podatke o treh podjetjih, ki vas zanimajo - Eastman Kodak, Cabot Corporation in Wal -Mart. Ker se podjetja razlikujejo po vrsti dejavnosti, ima vsaka časovna serija svoje edinstvene značilnosti. Zato je treba za napovedovanje uporabiti različne modele. Kako izbrati najboljši model napovedovanja za vsako podjetje? Kako oceniti naložbene možnosti na podlagi napovedanih rezultatov?
Razprava se začne z analizo letnih podatkov. Prikazani sta dve metodi glajenja teh podatkov: drseče povprečje in eksponentno glajenje. Nato prikaže postopek za izračun trenda z uporabo metode najmanjših kvadratov in bolj izpopolnjenih metod napovedovanja. Nazadnje so ti modeli razširjeni na časovne vrste na podlagi mesečnih ali četrtletnih podatkov.
Prenesite zapisek v obliki zapisa ali primere v obliki zapisa
Napovedovanje poslovanja
Ker se gospodarske razmere sčasoma spreminjajo, morajo menedžerji predvideti vpliv teh sprememb na njihovo podjetje. Eden od načinov za zagotovitev natančnega načrtovanja je napovedovanje. Kljub velikemu številu razvitih metod vsi sledijo istemu cilju - predvideti dogodke, ki se bodo zgodili v prihodnosti, da jih bodo upoštevali pri razvoju načrtov in strategij za razvoj podjetja.
Sodobna družba nenehno potrebuje napovedovanje. Na primer, za oblikovanje pravilne politike morajo člani vlade napovedati stopnjo brezposelnosti, inflacijo, industrijsko proizvodnjo, dohodnino in dohodnino. Za določitev opreme in potreb po osebju morajo direktorji letalskih prevoznikov pravilno predvideti obseg letalskih prevozov. Da bi ustvarili zadostno število mest v študentskih domovih, skrbniki fakultete ali univerze želijo vedeti, koliko študentov bo v naslednjem letu sprejetih na njihovo ustanovo.
Obstajata dva splošno sprejeta pristopa napovedovanja: kvalitativni in kvantitativni. Kvalitativne metode napovedovanja so še posebej pomembne, kadar raziskovalcu kvantitativni podatki niso na voljo. Običajno so te metode zelo subjektivne. Če so na voljo statistični podatki o zgodovini predmeta študija, je treba uporabiti metode kvantitativnega napovedovanja. Te metode omogočajo napovedovanje stanja predmeta v prihodnosti na podlagi podatkov o njegovi preteklosti. Kvantitativne metode napovedovanja spadajo v dve kategoriji: analiza časovnih vrst in metode vzročne analize.
Časovne serije je niz numeričnih podatkov, pridobljenih v zaporednih časovnih obdobjih. Analiza časovnih vrst vam omogoča, da predvidite vrednost številske spremenljivke na podlagi njenih preteklih in sedanjih vrednosti. Na primer, dnevne cene delnic na newyorški borzi tvorijo časovno vrsto. Drug primer časovne vrste so mesečni CPI, četrtletni bruto domači proizvod in letni prihodki od prodaje podjetja.
Metode za analizo vzročnih povezav vam omogočajo, da ugotovite, kateri dejavniki vplivajo na vrednosti napovedane spremenljivke. Ti vključujejo metode multiple regresijske analize z zaostajajočimi spremenljivkami, ekonometrično modeliranje, analizo vodilnih kazalnikov, metode za analizo indeksov difuzije in druge ekonomske kazalnike. Govorili bomo le o metodah napovedovanja na podlagi časovne analize. NS x vrstice.
Sestavine klasičnega multiplikativnega časovnega modela NS x vrstice
Glavna predpostavka pri analizi časovnih vrst je naslednja: dejavniki, ki vplivajo na predmet, ki ga preučujemo v sedanjosti in preteklosti, bodo nanj vplivali v prihodnosti. Tako so glavni cilji analize časovnih vrst ugotoviti in izpostaviti dejavnike, ki so pomembni za napovedovanje. Za dosego tega cilja so bili razviti številni matematični modeli, namenjeni raziskovanju nihanj komponent, vključenih v model časovnih vrst. Verjetno najpogostejši je klasični multiplikacijski model za letne, četrtletne in mesečne podatke. Za prikaz klasičnega multiplikativnega modela časovnih vrst upoštevajte podatke o dejanskem zaslužku Wm.Wrigleyja Jr. Podjetje za obdobje od 1982 do 2001 (slika 1).
Riž. 1. Graf dejanskega bruto dohodka Wm.Wrigleyja Jr. Podjetje (milijon dolarjev po trenutnih cenah) od leta 1982 do 2001
Kot lahko vidite, se je v zadnjih 20 letih dejanski bruto dohodek podjetja povečeval. Ta dolgoročni trend se imenuje trend. Trend ni edina sestavina časovne vrste. Poleg tega imajo podatki ciklične in nepravilne komponente. Ciklično komponenta opisuje nihanja podatkov navzgor in navzdol, pogosto v korelaciji s poslovnimi cikli. Njegova dolžina se giblje od 2 do 10 let. Intenzivnost ali amplituda ciklične komponente prav tako ni konstantna. V nekaterih letih so lahko podatki višji od vrednosti, ki jo napoveduje trend (t.j. v bližini vrha cikla), v drugih letih pa nižje (tj. Na dnu cikla). Vsi opazovani podatki, ki ne ležijo na krivulji trenda in niso podrejeni cikličnemu razmerju, se imenujejo nepravilni oz naključne komponente... Če se podatki beležijo dnevno ali četrtletno, se pojavi dodatna komponenta, imenovana sezonsko... Vse komponente časovnih vrst, značilne za gospodarske aplikacije, so prikazane na sl. 2.
Riž. 2. Dejavniki, ki vplivajo na časovno vrsto
Klasični multiplikativni model časovnih vrst navaja, da je vsaka opazovana vrednost produkt navedenih komponent. Če so podatki letni, opazovanje Yjaz ustrezne jaz-to leto, je izraženo z enačbo:
(1) Y i = T i* C i* Jaz i
kje T i- vrednost trenda, C i jaz-leto, Jaz i jaz leto.
Če se podatki merijo mesečno ali četrtletno, opazovanje Y i ki ustreza i -temu obdobju, je izraženo z enačbo:
(2) Y i = T i * S i * C i * I i
kje T i- vrednost trenda, S i je vrednost sezonske komponente v jaz-drugo obdobje, C i je vrednost ciklične komponente v jaz-drugo obdobje, Jaz i je vrednost naključne komponente v jaz-drugo obdobje.
Na prvi stopnji analize časovnih vrst se narišejo podatki in razkrije njihova odvisnost od časa. Najprej morate ugotoviti, ali se podatki dolgoročno povečujejo ali zmanjšujejo (tj. Trend), ali časovna vrsta niha okoli vodoravne črte. Če ni trenda, lahko za glajenje podatkov uporabimo drseče povprečje ali eksponentno glajenje.
Zglajevanje letnih časovnih vrst
V scenariju smo omenili Cabot Corporation. S sedežem v Bostonu v Massachusettsu je specializirano za proizvodnjo in prodajo kemikalij, gradbenih materialov, drobnih kemikalij, polprevodnikov in utekočinjenega zemeljskega plina. Podjetje ima 39 tovarn v 23 državah. Tržna vrednost podjetja je približno 1,87 milijard dolarjev, njegove delnice pa kotirajo na newyorški borzi pod kratico CBT. Prihodki podjetja za navedeno obdobje so prikazani na sl. 3.

Riž. 3. Prihodki družbe Cabot Corporation v letih 1982-2001 (milijarde dolarjev)
Kot lahko vidite, je dolgoročni trend naraščanja dohodka zakrit z velikim številom nihanj. Tako nam vizualna analiza grafikona ne omogoča trditve, da so podatki v trendu. V takih situacijah je mogoče uporabiti tehnike drsečega povprečja ali eksponentnega glajenja.
Drseča povprečja. Metoda drsečega povprečja je zelo subjektivna in je odvisna od dolžine obdobja L izbrano za izračun povprečja. Za izključitev cikličnih nihanj mora biti dolžina obdobja celoštevilčni večkratnik povprečne dolžine cikla. Drseča povprečja za izbrano dolžino L, tvorijo zaporedje sredstev, izračunano za sekvence dolžine L... Drseča povprečja so označena s simboli MA (L).
Recimo, da želimo izračunati petletno drseče povprečje iz podatkov, merjenih v teku n= 11 let. V kolikor L= 5, petletna drseča povprečja tvorijo zaporedje povprečij, izračunano iz petih zaporednih vrednosti časovnega niza. Prvo od petletnih drsečih povprečij se izračuna tako, da se prvih pet let sešteje in nato deli s pet:
![]()
Drugo petletno drseče povprečje se izračuna tako, da se seštejejo podatki za leta 2 do 6 in nato delijo s petimi:
![]()
Ta proces se nadaljuje, dokler se v zadnjih petih letih ne izračuna drseče povprečje. Pri delu z letnimi podatki je treba predvideti število L(dolžina obdobja, izbranega za izračun drsečih povprečij) je liha. V tem primeru ni mogoče izračunati drsečih povprečij za prvo ( L- 1) / 2 in zadnji ( L- 1) / 2 leti. Zato pri delu s petletnimi drsečimi povprečji ni mogoče izvesti izračunov za prva dva in zadnji dve leti. Leto, za katero se izračuna drseče povprečje, mora biti sredi dolgega obdobja L... Če n= 11, a L= 5, prvo drseče povprečje mora ustrezati tretjemu letu, drugo četrtemu in zadnje devetemu. Na sl. 4 prikazuje grafikone 3- in 7-letnih drsečih povprečij, izračunanih za zaslužek družbe Cabot Corporation od leta 1982 do 2001.

Riž. 4. Grafi 3- in 7-letnih drsečih povprečij, izračunani za dohodek družbe Cabot Corporation
Upoštevajte, da se pri izračunu 3-letnega drsečega povprečja opažene vrednosti za prvo in zadnje leto ne upoštevajo. Podobno pri izračunu sedemletnih drsečih povprečij ni rezultatov za prvo in zadnja tri leta. Poleg tega 7-letno drseče povprečje gladi časovno vrsto veliko bolj kot 3-letno. To je zato, ker ima 7-letno drseče povprečje daljše obdobje. Na žalost, dlje ko je obdobje, manj drsnih povprečij je mogoče izračunati in predstaviti na grafikonu. Zato je za izračun drsečih povprečij nezaželeno izbrati več kot sedem let, saj bo od začetka in konca grafikona izpadlo preveč točk, kar bo izkrivilo obliko časovnega niza.
Eksponentno glajenje. Za identifikacijo dolgoročnih trendov, ki so značilni za spremembe podatkov, razen drsečih povprečij, se uporablja metoda eksponentnega glajenja. Ta metoda vam omogoča tudi kratkoročne napovedi (v enem obdobju), kadar je obstoj dolgoročnih trendov vprašljiv. Zaradi tega ima metoda eksponentnega glajenja znatno prednost pred metodo drsečega povprečja.
Metoda eksponentnega glajenja je dobila ime po zaporedju eksponentno tehtanih drsečih povprečij. Vsaka vrednost v tem zaporedju je odvisna od vseh predhodnih opazovanih vrednosti. Druga prednost metode eksponentnega glajenja pred metodo drsečega povprečja je, da se pri uporabi slednje nekatere vrednosti zavržejo. Z eksponentnim glajenjem se uteži, dodeljene opazovanim vrednostim, sčasoma zmanjšujejo, tako da se po opravljenem izračunu najpogostejše vrednosti tehtajo največ, redke pa najmanj. Kljub ogromni količini izračunov vam Excel omogoča uporabo metode eksponentnega glajenja.
Enačba, ki časovno vrsto poravna v poljubnem časovnem obdobju jaz, vsebuje tri člane: trenutno opazovano vrednost Yjaz, ki pripada časovni vrsti, prejšnja eksponentno zglajena vrednost Ejaz –1 in določeno težo W.
(3) E 1 = Y 1 E i = WY i + (1 - W) E i - 1, i = 2, 3, 4,…
kje Ejaz- vrednost eksponentno zglajene serije, izračunana za jaz-drugo obdobje, E i –1 Ali je vrednost eksponentno zglajene serije izračunana za ( jaz- 1) - pojdi na obdobje, Y i- opazovana vrednost časovne vrste v jaz-drugo obdobje, W- subjektivna teža ali koeficient glajenja (0< W < 1).
Izbira faktorja glajenja ali teže, dodeljene članom serije, je ključnega pomena, ker neposredno vpliva na rezultat. Žal je ta izbira nekoliko subjektivna. Če želi raziskovalec izključiti neželena ciklična ali naključna nihanja iz časovne vrste, je treba izbrati majhne vrednosti W(blizu ničle). Po drugi strani pa je treba za napovedovanje časovne vrste izbrati veliko težo W(blizu enega). V prvem primeru se jasno kažejo dolgoročni trendi časovne vrste. V drugem primeru se poveča natančnost kratkoročnega napovedovanja (slika 5).

Riž. 5 grafikonov eksponentno zglajenih časovnih vrst (W = 0,50 in W = 0,25) za podatke o zaslužku podjetja Cabot Corporation od leta 1982 do 2001; formule za izračun glejte datoteko Excel
Eksponentno zglajena vrednost, dobljena za jaz-ti časovni interval, se lahko uporabi kot ocena predvidene vrednosti v ( jaz+1) -ti interval:
![]()
Napovedati prihodke družbe Cabot Corporation v letu 2002 na podlagi eksponentno zglajene časovne vrste, ki ustreza teži W= 0,25, lahko uporabimo zglajeno vrednost, izračunano za leto 2001. Sl. Slika 5 prikazuje, da je ta vrednost enaka 1.651,0 milijona USD. Ko bodo na voljo podatki o prihodkih družbe v letu 2002, lahko uporabimo enačbo (3) in predvidemo raven prihodkov v letu 2003 z uporabo zglajene vrednosti prihodkov v letu 2002:
Paket analiz Excel lahko z enim klikom nariše eksponentno glajenje. Pojdite skozi meni Podatki → Analiza podatkov in izberite možnost Eksponentno glajenje(slika 6). V odprtem oknu Eksponentno glajenje nastavite parametre. Na žalost vam postopek omogoča, da sestavite samo eno zglajeno vrstico, zato, če se želite igrati s parametrom W, ponovite postopek.

Riž. 6. Narišite eksponentno glajenje z uporabo analiznega paketa
Trendi in napovedovanje najmanjših kvadratov
Med sestavinami časovne vrste se najpogosteje preučuje trend. To je trend, ki vam omogoča kratkoročne in dolgoročne napovedi. Za identifikacijo dolgoročnega trenda v časovni vrsti se običajno nariše graf, na katerem so na navpični osi narisani opazovani podatki (vrednosti odvisne spremenljivke), časovni intervali (vrednosti neodvisne spremenljivke) pa narisano na vodoravni osi. V tem razdelku opisujemo postopek odkrivanja linearnih, kvadratnih in eksponentnih trendov z uporabo metode najmanjših kvadratov.
Linearni trendni model je najpreprostejši model za napovedovanje: Y i = β 0 + β 1 X i + ε i. Linearna enačba trenda:
![]()
Pri dani stopnji pomembnosti α se ničelna hipoteza zavrne, če je test t-statistika večja od zgornje ali manjše od spodnje kritične ravni t-razdelitve. Z drugimi besedami, pravilo odločanja je oblikovano tako: če t > tU ali t < t L, ničelna hipoteza H 0 se zavrne, sicer ničelna hipoteza ni zavrnjena (slika 14).

Riž. 14. Področja zavračanja hipoteze za dvostranski test pomembnosti parametra avtoregresije A r z najvišjim redom
Če ničelna hipoteza ( A r= 0) ne zavrne, kar pomeni, da izbrani model vsebuje preveč parametrov. Merilo vam omogoča, da zavržete starejšega člana modela in ocenite avtoregresivni model reda p - 1... Ta postopek je treba nadaljevati do ničelne hipoteze H 0 ne bo zavrnjen.
Za prikaz avtoregresivnega modeliranja se vrnimo k analizi časovnih vrst dejanskega zaslužka podjetja Wm. Wrigley Jr. Na sl. 15 prikazuje podatke, potrebne za izdelavo avtoregresivnih modelov prvega, drugega in tretjega reda. Vsi stolpci te tabele so potrebni za izdelavo modela tretjega reda. Pri izdelavi avtoregresivnega modela drugega reda se zadnji stolpec prezre. Pri izdelavi avtoregresivnega modela prvega reda se zadnja dva stolpca ne upoštevata. Tako so pri konstruiranju avtoregresivnih modelov prvega, drugega in tretjega reda ena, dve oziroma trije izključeni iz 20 spremenljivk.

Izbira najbolj natančnega avtoregresivnega modela se začne z modelom tretjega reda. Za pravilno delo Paket analiz sledi kot vnosni interval Y določite obseg B5: B21 in vnosni interval za NS- C5: E21. Podatki analize so prikazani na sl. 16.

Preverite pomembnost parametra A 3 z najvišjim redom. Njegova ocena a 3 je –0,006 (celica C20 na sliki 16), standardna napaka pa 0,326 (celica D20). Za preverjanje hipotez H 0: A 3 = 0 in H 1: A 3 ≠ 0 izračunamo t-statistika:

t-merila z n -2p -1 = 20–2 * 3–1 = 13 stopinj svobode so enaka: t L= STUDENT.OBR (0,025; 13) = –2,160; t U= STUDENT.OBR (0.975,13) = +2.160. Od -2.160< t = –0,019 < +2,160 и R= 0,985> α = 0,05, ničelna hipoteza H 0 ni mogoče zavrniti. Tako parameter tretjega reda nima statističnega pomena v avtoregresivnem modelu in ga je treba odstraniti.
Ponovimo analizo za avtoregresivni model drugega reda (slika 17). Ocena parametra najvišjega reda, a 2= –0,205, standardna napaka pa 0,276. Za preverjanje hipotez H 0: A 2 = 0 in H 1: A 2 ≠ 0 izračunamo t-statistika:


Na ravni pomembnosti α = 0,05 so kritične vrednosti dvostranske t-merila z n -2p -1 = 20–2 * 2–1 = 15 stopinj svobode so enaka: t L= STUDENT.OBR (0,025; 15) = –2,131; t U= STUDENT.OBR (0.975,15) = +2.131. Od –2.131< t = –0,744 < –2,131 и R= 0,469> α = 0,05, ničelna hipoteza H 0 ni mogoče zavrniti. Tako parameter drugega reda ni statistično pomemben in ga je treba odstraniti iz modela.
Ponovimo analizo za avtoregresivni model prvega reda (slika 18). Ocena parametra najvišjega reda, a 1= 1,024, standardna napaka pa 0,039. Za preverjanje hipotez H 0: A 1 = 0 in H 1: A 1 ≠ 0 izračunamo t-statistika:


Na ravni pomembnosti α = 0,05 so kritične vrednosti dvostranske t-merila z n -2p -1 = 20–2 * 1–1 = 17 stopinj svobode so enaka: t L= STUDENT.OBR (0,025; 17) = –2,110; t U= STUDENT.OBR (0,975; 17) = +2,110. Od -2.110< t = 26,393 < –2,110 и R = 0,000 < α = 0,05, нулевую гипотезу H 0 je treba zavrniti. Tako je parameter prvega reda statistično pomemben in ga ni mogoče odstraniti iz modela. Tako je avtoregresivni model prvega reda najboljši približek prvotnih podatkov. Uporaba ocen a 0 = 18,261, a 1= 1,024 in vrednost časovne vrste za zadnje leto - Y 20 = 1 371,88, je mogoče predvideti vrednost realnega dohodka družbe Wm. Wrigley Jr. Podjetje leta 2002:
Izbira ustreznega modela napovedovanja
Zgoraj je bilo opisanih šest metod za napovedovanje časovnih vrst: linearni, kvadratni in eksponentni modeli trendov ter avtoregresivni modeli prvega, drugega in tretjega reda. Ali obstaja optimalen model? Katerega od šestih opisanih modelov je treba uporabiti za napovedovanje vrednosti časovne vrste? Spodaj so navedena štiri načela, ki bi morala voditi pri izbiri ustreznega modela napovedovanja. Ta načela temeljijo na ocenah natančnosti modelov. Predpostavlja se, da je mogoče vrednosti časovne vrste predvideti s preučevanjem njenih prejšnjih vrednosti.
Načela izbire modelov za napovedovanje:
Preostala analiza. Spomnite se, da je preostanek razlika med predvideno vrednostjo in opazovano vrednostjo. Ko ste zgradili model za časovno vrsto, morate za vsako izračunati ostanke n intervalih. Kot je prikazano na sl. 19, plošča A, če je model ustrezen, ostanki predstavljajo naključno komponento časovnega niza in so zato nepravilno porazdeljeni. Po drugi strani pa, kot je prikazano na preostalih ploščah, lahko ostanek, če model ni ustrezen, ima sistematično razmerje, ki ne upošteva niti trenda (plošča B), niti cikličnega (plošča C) ali sezonskega komponenta (plošča D).

Riž. 19. Analiza ostankov
Merjenje absolutnih in korenskih preostalih napak.Če analiza ostankov ne omogoča določitve enega samega ustreznega modela, lahko uporabite druge metode, ki temeljijo na oceni obsega preostale napake. Na žalost statistiki niso dosegli soglasja o najboljši oceni preostalih napak pri modelih, uporabljenih za napovedovanje. Na podlagi načela najmanjših kvadratov lahko najprej izvedete regresijsko analizo in izračunate standardno napako ocene S XY... Pri analizi določenega modela je ta vrednost vsota kvadratov razlik med dejanskimi in napovedanimi vrednostmi časovnega niza. Če model popolnoma ustreza vrednostim časovnih vrst v prejšnjih časovnih točkah, je standardna napaka ocene nič. Po drugi strani pa, če model slabo približa vrednosti časovnih vrst v prejšnjih časovnih točkah, je standardna napaka ocene velika. Tako lahko z analizo ustreznosti več modelov izberemo model z minimalno standardno napako ocene S XY.
Glavna pomanjkljivost tega pristopa je pretiravanje napak pri napovedovanju posameznih vrednosti. Z drugimi besedami, vsaka velika razlika med količinami Yjaz in Ŷ jaz pri izračunu vsote napak na kvadrat je SSE na kvadrat, t.j. povečuje. Zaradi tega mnogi statistiki raje uporabljajo povprečno absolutno odstopanje (MAD) za oceno ustreznosti modela napovedovanja:

Pri analizi posebnih modelov je vrednost MAD povprečna vrednost absolutnih vrednosti razlik med dejanskimi in napovedanimi vrednostmi časovnega niza. Če se model popolnoma ujema z vrednostmi časovnih vrst v prejšnjih časovnih točkah, je povprečno absolutno odstopanje nič. Po drugi strani pa, če model slabo približuje vrednosti časovnih vrst, je povprečno absolutno odstopanje veliko. Tako je z analizo ustreznosti več modelov mogoče izbrati model, ki ima minimalno povprečno absolutno odstopanje.
Načelo ekonomičnosti.Če analiza standardnih napak ocen in srednjih absolutnih odstopanj ne omogoča določitve optimalnega modela, lahko uporabite četrto metodo, ki temelji na načelu ekonomičnosti. To načelo pravi, da je treba najpreprostejšega izbrati med več enakimi modeli.
Od šestih modelov napovedovanja, obravnavanih v tem poglavju, sta najpreprostejša linearni in kvadratni regresijski model ter avtoregresivni model prvega reda. Preostali modeli so veliko bolj zapleteni.
Primerjava štirih metod napovedovanja. Za ponazoritev postopka izbire optimalnega modela se vrnimo k časovnim vrstam, ki jih sestavljajo vrednosti realnih prihodkov podjetja Wm. Wrigley Jr. Podjetje. Primerjajmo štiri modele: linearne, kvadratne, eksponentne in avtoregresivne modele prvega reda. (Avtoregresivni modeli drugega in tretjega reda le nekoliko izboljšajo natančnost napovedovanja vrednosti dane časovne vrste, zato jih je mogoče prezreti.) 20 prikazuje ploskev ostankov, zgrajenih z analizo štirih metod napovedovanja z uporabo Paket analiz Excel. Pri sklepanju iz teh grafov bodite previdni, saj časovna vrsta vsebuje le 20 točk. Za načine gradnje glejte ustrezen list v Excelovi datoteki.

Riž. 20. Parcele ostankov, izdelane z analizo štirih metod napovedovanja z uporabo Paket analiz Excel
Noben drug model razen avtoregresivnega modela prvega reda ne upošteva ciklične komponente. Ta model se bolj kot drugi približuje opazovanjem in ga odlikuje najmanj sistematična struktura. Torej je analiza ostankov vseh štirih metod pokazala, da je avtoregresivni model prvega reda najboljši, linearni, kvadratni in eksponentni modeli pa imajo manjšo natančnost. Za preverjanje primerjajmo preostale napake teh metod (slika 21). Z načinom izračuna se lahko seznanite tako, da odprete datoteko Excel. Na sl. 21 so dejanske vrednosti Y i(zvočnik Realni dohodek), predvidene vrednosti Ŷ jaz pa tudi ostanki ejaz za vsakega od štirih modelov. Poleg tega so prikazane vrednosti SYX in MAD... Za vse štiri modele so količine SYX in MAD približno enako. Eksponencialni model je relativno slabši, linearni in kvadratni modeli pa so natančnejši. Po pričakovanjih najmanjše vrednosti SYX in MAD ima avtoregresivni model prvega reda.

Riž. 21. Primerjava štirih metod napovedovanja s kazalniki S YX in MAD
Ko smo izbrali poseben model napovedovanja, je treba natančno spremljati nadaljnje spremembe časovnega niza. Med drugim je tak model ustvarjen za pravilno napoved vrednosti časovnih vrst v prihodnosti. Na žalost takšni modeli napovedovanja slabo upoštevajo spremembe v strukturi časovne vrste. Nujno je treba primerjati ne le preostalo napako, temveč tudi natančnost napovedovanja prihodnjih vrednosti časovnih vrst, pridobljenih s pomočjo drugih modelov. Ko smo izmerili novo vrednost Yjaz v opazovanem časovnem intervalu ga je treba takoj primerjati s predvideno vrednostjo. Če je razlika prevelika, je treba model napovedi revidirati.
Napoved časa NS x serije na podlagi sezonskih podatkov
Doslej smo preučevali časovno vrsto, sestavljeno iz letnih podatkov. Številne časovne vrste pa so sestavljene iz količin, merjenih četrtletno, mesečno, tedensko, dnevno in celo na uro. Kot je prikazano na sl. 2, če se podatki merijo mesečno ali četrtletno, je treba upoštevati sezonsko komponento. V tem razdelku bomo pogledali metode za napovedovanje vrednosti takšnih časovnih vrst.
Scenarij, opisan na začetku poglavja, se nanaša na Wal-Mart Stores, Inc. Tržna kapitalizacija družbe je 229 milijard USD. Njene delnice kotirajo na newyorški borzi pod akronimom WMT. Poslovno leto družbe se konča 31. januarja, zato četrto četrtletje 2002 vključuje novembra in december 2001 ter januar 2002. Časovni niz četrtletnih prihodkov družbe je prikazan na sl. 22.

Riž. 22. Wal-Mart Stores, Inc. Četrtletni prihodki (Milijoni USD)
Za četrtletne serije, kot je ta, klasični multiplikacijski model poleg trendovskih, cikličnih in naključnih komponent vsebuje sezonsko komponento: Y i = T i* S i* C i* Jaz i
Napovedovanje menstruacije in časa NS x vrstic po metodi najmanjših kvadratov. Regresijski model s sezonsko komponento temelji na kombiniranem pristopu. Za izračun trenda se uporablja prej opisana metoda najmanjših kvadratov in upošteva sezonska komponenta - kategorična spremenljivka (za več podrobnosti glejte poglavje Lažni regresijski modeli in učinki interakcije). Za približevanje časovnega niza s sezonskimi komponentami se uporablja eksponentni model. V modelu, ki približuje četrtletno časovno vrsto, smo potrebovali tri lažne spremenljivke, ki so upoštevale štiri četrtine V1, V2 in V3, v modelu za mesečno časovno vrsto pa je 12 mesecev predstavljenih z 11 lažnimi spremenljivkami. Ker ti modeli uporabljajo spremenljivko log Y i, vendar ne Y i, za izračun resničnih regresijskih koeficientov je treba izvesti obratno transformacijo.
Za ponazoritev procesa oblikovanja četrtletnega modela časovnih vrst se vrnimo k zaslužkom družbe Wal-Mart. Parametri eksponentnega modela, dobljeni z uporabo Paket analiz Excel sta prikazana na sl. 23.

Riž. 23. Regresijska analiza četrtletnega zaslužka družbe Wal-Mart Stores, Inc.
Vidimo, da se eksponentni model precej dobro približa prvotnim podatkom. Mešani korelacijski koeficient r 2 je 99,4% (celice J5), popravljeni koeficient mešane korelacije je 99,3% (celice J6), preskus F.-statistika - 1.333,51 (celice M12), in R-vrednost je 0,0000. Pri ravni pomembnosti α = 0,05 je vsak regresijski koeficient v klasičnem multiplikativnem modelu časovnih vrst statistično pomemben. Z uporabo operacije potenciranja dobimo naslednje parametre:

Kvote ![]() se razlagajo na naslednji način.
se razlagajo na naslednji način.
Uporaba regresijskih koeficientov b i, lahko predvidevate dohodek, ki ga bo podjetje prejelo v določenem četrtletju. Na primer, predvidejmo prihodke podjetja za četrto četrtletje 2002 ( Xjaz = 35):
log = b 0 + b 1 NSjaz = 4,265 + 0,016*35 = 4,825
= 10 4,825 = 66 834
Tako bi morala družba po napovedi v četrtem četrtletju 2002 prejeti 67 milijard dolarjev prihodkov (komaj je treba napovedati na milijon). Za podaljšanje napovedi za časovno obdobje zunaj časovnega niza, na primer za prvo četrtletje leta 2003 ( Xjaz = 36, V1= 1), morate izvesti naslednje izračune:
dnevnik Ŷ i = b 0 + b 1NSjaz + b 2 Q 1 = 4,265 + 0,016*36 – 0,093*1 = 4,748
10 4,748 = 55 976
Indeksi
Indeksi se uporabljajo kot kazalniki, ki se odzivajo na spremembe gospodarskih razmer ali poslovne dejavnosti. Obstajajo številne vrste indeksov, kot so indeksi cen, količinski indeksi, indeksi vrednosti in sociološki indeksi. V tem razdelku bomo upoštevali le indeks cen. Kazalo- vrednost nekega ekonomskega kazalnika (ali skupine kazalnikov) v določenem trenutku, izražena kot odstotek njegove vrednosti na izhodiščni točki v času.
Indeks cen. Preprost indeks cen odraža odstotno spremembo cene izdelka (ali skupine izdelkov) v določenem časovnem obdobju v primerjavi s ceno tega izdelka (ali skupine izdelkov) v določenem trenutku v preteklosti. Pri izračunu indeksa cen morate najprej izbrati osnovni časovni interval - časovni interval v preteklosti, s katerim bodo narejene primerjave. Pri izbiri osnovnega obdobja za določen indeks so obdobja gospodarske stabilnosti boljša od obdobij gospodarskega okrevanja ali recesije. Poleg tega izhodišče ne sme biti časovno preveč oddaljeno, tako da na rezultate primerjave ne vplivajo preveč močne spremembe tehnologije in potrošniških navad. Indeks cen se izračuna po formuli:

kje Jaz i- indeks cen v jaz-m leto, Rjaz- cena v jaz-m leto, P baze- cena v baznem letu.
Indeks cen je odstotna sprememba cene izdelka (ali skupine izdelkov) v določenem časovnem obdobju glede na ceno izdelka v izhodiščnem času. Za primer razmislite o ameriškem indeksu cen neosvinčenega bencina med letoma 1980 in 2002 (slika 24). Na primer:


Riž. 24. Cena galone neosvinčenega bencina in preprost indeks cen v Združenih državah od 1980 do 2002 (izhodiščna leta - 1980 in 1995)
Tako je bila leta 2002 cena neosvinčenega bencina v Združenih državah za 4,8% višja kot leta 1980. Analiza sl. 24 prikazuje, da je indeks cen v letih 1981 in 1982. je bil leta 1980 višji od indeksa cen, nato pa do leta 2000 ni presegel osnovne ravni. Ker je za bazno obdobje izbrano leto 1980, je verjetno smiselno izbrati bližje leto, na primer 1995. Formula za ponovni izračun indeksa glede na novo osnovno časovno obdobje je:

kje jaznov- nov indeks cen, jazstar- stari indeks cen, jaznov base - vrednost indeksa cen v novem baznem letu pri izračunu za staro bazno leto.
Predpostavimo, da je za novo bazo izbrano leto 1995. S formulo (10) dobimo nov indeks cen za leto 2002:
Tako je leta 2002 neosvinčeni bencin v ZDA stal 13,9% več kot leta 1995.
Netehtani sestavljeni indeksi cen. Kljub temu, da je indeks cen za vsak posamezen izdelek nedvomno zanimiv, je pomembnejši indeks cen za skupino blaga, ki omogoča oceno stroškov in življenjskega standarda velikega števila potrošnikov. Netehtani sestavljeni indeks cen, opredeljen s formulo (11), pripisuje enako težo vsakemu posameznemu blagu. Sestavljeni indeks cen odraža odstotno spremembo cene skupine blaga (pogosto imenovane košarica blaga) v določenem časovnem obdobju glede na ceno te skupine blaga na izhodiščni točki.

kje t jaz- številka postavke (1, 2, ..., n), n- število blaga v obravnavani skupini, - vsota cen za vsako od n blago pravočasno t, je vsota cen za vsako od n blago v ničelnem časovnem obdobju je vrednost netehtanega sestavljenega indeksa v časovnem obdobju t.
Na sl. 25 prikazuje povprečne cene treh vrst sadja za obdobje od 1980 do 1999. Za izračun netehtanega sestavljenega indeksa cen v različnih letih se uporablja formula (11), pri čemer se 1980 upošteva kot bazno leto.
Tako je bila leta 1999 skupna cena kilograma jabolk, funt banan in funt pomaranč 59,4% višja od skupne cene tega sadja leta 1980.

Riž. 25. Cene (v dolarjih) za tri vrste sadja in netehtani sestavljeni indeks cen
Netehtani sestavljeni indeks cen izraža spremembe cen za celotno skupino blaga skozi čas. Čeprav je ta indeks enostaven za izračun, ima dve ločeni pomanjkljivosti. Prvič, pri izračunu tega indeksa se vse vrste blaga štejejo za enako pomembne, zato drago blago pridobi nepotreben vpliv na indeks. Drugič, ne porabi se vse blago enako, zato imajo spremembe cen za blago z nizko porabo preveč vpliva na netehtani indeks.
Uteženi sestavljeni indeksi cen. Zaradi pomanjkljivosti netehtanih indeksov cen so prednostni tehtani indeksi cen, ki upoštevajo razlike v cenah in stopnjah porabe blaga, ki tvorijo potrošniško košarico. Obstajata dve vrsti tehtanih sestavljenih indeksov cen. Lapeyrejev indeks cen opredeljeno s formulo (12) uporablja ravni porabe v baznem letu. Tehtani sestavljeni indeks cen upošteva stopnjo porabe blaga, ki sestavlja potrošniško košarico, tako da vsakemu izdelku dodeli določeno težo.

kje t- časovno obdobje (0, 1, 2, ...), jaz- številka postavke (1, 2, ..., n), n jaz v ničelnem časovnem obdobju je vrednost indeksa LaPeyre v časovnem obdobju t.
Izračuni Lapeyrovega indeksa so prikazani na sl. 26; Leto 1980 se uporablja kot izhodišče.

Riž. 26. Cene (v dolarjih), količina (poraba v funtih na prebivalca) treh vrst sadja in indeks LaPeyre
Tako je Lapeyrejev indeks leta 1999 154,2. To kaže, da so bile leta 1999 te tri vrste sadja za 54,2% dražje kot leta 1980. Upoštevajte, da je ta indeks nižji od netehtanega indeksa 159,4, saj so se cene pomaranč - najmanj porabljenega sadja - zvišale bolj kot cene jabolk in banan. Z drugimi besedami, ker so se cene najbolj porabljenega sadja zvišale manj kot cene pomaranč, je indeks Lapeyre manjši od netehtanega sestavljenega indeksa.
Paaschejev indeks cen uporablja porabo izdelka v trenutnem, ne v osnovnem časovnem obdobju. Zato Paaschejev indeks natančneje odraža skupne stroške porabe blaga v danem trenutku. Vendar ima ta indeks dve pomembni pomanjkljivosti. Prvič, običajno je težko določiti trenutno raven porabe. Zaradi tega mnogi priljubljeni indeksi uporabljajo indeks LaPeyre in ne indeks Paasche. Drugič, če cena določenega blaga v potrošniški košarici močno naraste, kupci zmanjšajo porabo zaradi potrebe, ne zaradi spremembe okusov. Paaschejev indeks se izračuna po formuli:

kje t- časovno obdobje (0, 1, 2, ...), jaz- številka postavke (1, 2, ..., n), n- število izdelkov v obravnavani skupini, - število enot izdelka jaz v ničelnem časovnem obdobju je vrednost Paaschejevega indeksa v časovnem obdobju t.
Izračuni Paaschejevega indeksa so prikazani na sl. 27; Leto 1980 se uporablja kot izhodišče.

Riž. 27. Cene (v dolarjih), količina (poraba v funtih na prebivalca) treh vrst sadja in Paaschejev indeks
Torej je indeks Paasche leta 1999 147,0. To kaže, da so bile leta 1999 te tri vrste sadja 47,0% dražje kot leta 1980.
Nekaj priljubljenih indeksov cen. V gospodarstvu in gospodarstvu se uporablja več indeksov cen. Najbolj priljubljen je indeks cen življenjskih potrebščin (CPI). Uradno se ta indeks imenuje CPI-U, da bi poudaril, da se izračuna za mesta (urbana), čeprav se običajno imenuje preprosto CPI. Ta indeks mesečno objavlja Urad ZDA za statistiko dela kot primarno orodje za merjenje življenjskih stroškov v Združenih državah. Indeks cen življenjskih potrebščin je sestavljen in utežen po metodi Lapeyre. Izračuna se na podlagi cen 400 najpogosteje porabljenih izdelkov, vrst oblačil, prevoza, medicinskih in komunalnih storitev. Trenutno se pri izračunu tega indeksa kot osnova uporablja obdobje 1982–1984. (slika 28). Pomembna funkcija CPI je njegova uporaba kot deflatorja. CPI se uporablja za pretvorbo dejanskih cen v realne cene tako, da se vsaka cena pomnoži s faktorjem 100 / CPI. Izračuni kažejo, da je bila v zadnjih 30 letih povprečna letna stopnja inflacije v ZDA 2,9%.

Riž. 28. Dinamika cen indeksa potrošnikov; za podrobnosti glejte datoteko Excel
Drug pomemben indeks cen, ki ga je objavil Urad za statistiko dela, je Indeks cen proizvajalcev (PPI). PPI je tehtani sestavljeni indeks, ki uporablja metodo Lapeyre za oceno spremembe cen blaga, ki ga prodajajo njihovi proizvajalci. PPI je vodilni kazalnik CPI. Z drugimi besedami, povečanje IPC vodi do povečanja CPI in obratno, zmanjšanje IPC vodi do zmanjšanja CPI. Za merjenje sprememb vrednosti ameriških delnic se uporabljajo finančni indeksi, kot so Dow Jones Industrial Average (DJIA), S&P 500 in NASDAQ. Številni indeksi merijo donosnost mednarodnih delniških trgov. Ti indeksi vključujejo Nikkei na Japonskem, Dax 30 v Nemčiji in SSE Composite na Kitajskem.
Pasti, povezane z analizo časa NS x vrstice
Pomen metodologije, ki uporablja podatke o preteklosti in sedanjosti za napovedovanje prihodnosti, je državnik Patrick Henry zgovorno opisal pred več kot dvesto leti: »Imam samo eno svetilko, ki osvetljuje pot - moje izkušnje. Samo poznavanje preteklosti nam omogoča presojo prihodnosti. "
Analiza časovnih vrst temelji na predpostavki, da bodo dejavniki, ki vplivajo na poslovno aktivnost v preteklosti in vplivajo na sedanjost, delovali tudi v prihodnje. Če je res, je analiza časovnih vrst učinkovito orodje za napovedovanje in upravljanje. Vendar pa kritiki klasičnih metod, ki temeljijo na analizi časovnih vrst, trdijo, da so te metode preveč naivne in primitivne. Z drugimi besedami, matematični model, ki upošteva dejavnike, ki so delovali v preteklosti, ne bi smel mehansko ekstrapolirati trendov v prihodnost, ne da bi upošteval strokovne ocene, poslovne izkušnje, spremembe v tehnologiji ter navade in potrebe ljudi. V prizadevanjih za odpravo te situacije so v zadnjih letih ekonometriki razvili sofisticirane računalniške modele gospodarske dejavnosti, ki upoštevajo zgoraj naštete dejavnike.
Vendar so metode analize časovnih vrst odlično orodje za napovedovanje (tako kratkoročno kot dolgoročno), če se pravilno uporabljajo v kombinaciji z drugimi metodami napovedovanja ter strokovno presojo in izkušnjami.
Povzetek. V tej opombi so z analizo časovnih vrst razvili modele za napovedovanje prihodkov treh podjetij: Wm. Wrigley Jr. Company, Cabot Corporation in Wal-Mart. Opisani so sestavni deli časovnega niza ter več pristopov k napovedovanju letnih časovnih vrst - metoda drsečega povprečja, metoda eksponentnega glajenja, linearni, kvadratni in eksponentni model ter avtoregresivni model. Upoštevan je regresijski model, ki vsebuje lažne spremenljivke, ki ustrezajo sezonski komponenti. Prikazana je uporaba metode najmanjših kvadratov za napovedovanje mesečnih in četrtletnih časovnih vrst (slika 29).
P stopnje svobode se izgubijo pri primerjavi vrednosti časovnih vrst.
Analiza časovnih vrst vam omogoča, da skozi čas raziščete kazalnike. Časovne vrste so številske vrednosti statistike v kronološkem vrstnem redu.
Takšni podatki so pogosti na različnih področjih človekove dejavnosti: dnevne cene delnic, menjalni tečaji, četrtletno, letna prodaja, proizvodnja itd. Tipične časovne vrste v meteorologiji, na primer mesečne padavine.
Če vrednosti procesa popravljate v rednih časovnih presledkih, dobite elemente časovne vrste. Svojo variabilnost poskušajo razdeliti na redne in naključne komponente. Naravne spremembe v članih serije so običajno predvidljive.
Naredimo analizo časovnih vrst v Excelu. Primer: Trgovska veriga analizira podatke o prodaji blaga po trgovinah v mestih z manj kot 50.000 prebivalci. Obdobje - 2012-2015 Naloga je opredeliti glavni razvojni trend.
Podatke o izvajanju vnesemo v Excelovo preglednico:
Na zavihku "Podatki" kliknite gumb "Analiza podatkov". Če ni viden, pojdite v meni. Možnosti programa Excel - dodatki. Na dnu kliknite »Pojdi« do »Dodatki Excel« in izberite »Paket za analizo«.
Podrobno je opisana povezava nastavitve "Analiza podatkov".
Želeni gumb se prikaže na traku.

Na predlaganem seznamu orodij za statistično analizo izberite "Eksponentno glajenje". Ta metoda poravnave je primerna za naše časovne vrste, katerih vrednosti močno nihajo.
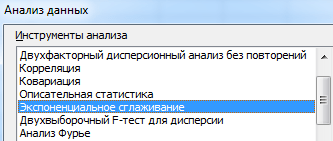
Izpolnimo pogovorno okno. Vnosni interval je obseg s prodajnimi vrednostmi. Faktor dušenja - faktor eksponentnega glajenja (privzeto 0,3). Output Range je sklic na zgornjo levo celico izhodnega območja. Program bo tu postavil zglajene ravni in sam določil velikost. Postavili smo potrditvena polja »Izhod grafa«, »Standardne napake«.
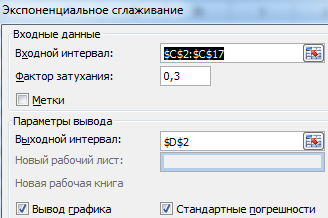
Zaprite pogovorno okno s klikom na V redu. Rezultati analize:

Excel za izračun standardnih napak uporablja formulo: = ROOT (SUMKVRAZN ('obseg dejanskih vrednosti'; 'obseg predvidenih vrednosti') / 'velikost okna za glajenje'). Na primer = ROOT (SUMXTRASN (C3: C5; D3: D5) / 3).
Naredimo prodajno napoved s podatki iz prejšnjega primera.
Grafu dodajte linijo trenda, ki prikazuje dejanski obseg prodaje (desni gumb na grafu - "Dodaj črto trenda").
Prilagodite parametre linije trenda:

Za zmanjšanje napake pri modelu napovedi se odločimo za polinomski trend.

R2 = 0,9567, kar pomeni, da to razmerje pojasnjuje 95,67% sprememb obsega prodaje skozi čas.
Enačba trenda je model formule za izračun predvidenih vrednosti.
Dobimo dokaj optimističen rezultat:

V našem primeru je še vedno eksponentna odvisnost. Zato je pri izgradnji linearnega trenda več napak in netočnosti.
Funkcijo GROWTH lahko uporabite tudi za napovedovanje eksponentnih razmerij v Excelu.

Za linearno odvisnost - TREND.
Pri napovedovanju ne morete uporabiti nobene metode: obstaja velika verjetnost velikih odstopanj in netočnosti.
07.10.2013 Tyler Chessman
Razumevanje ključnih zamisli o napovedovanju časovnih vrst in poznavanje nekaterih podrobnosti vam bo dalo prednost pri uporabi zmogljivosti napovedovanja storitev SQL Server Analysis Services (SSAS)
Ta članek bo opisal osnovne koncepte, potrebne za obvladovanje tehnologij rudarjenja podatkov. Zajeli bomo tudi nekatere subtilnosti, da se v praksi ne boste zmotili (glejte stransko vrstico »Zakaj je rudarjenje podatkov tako nepriljubljeno«).
Občasno morajo strokovnjaki SQL Serverja narediti projekcije prihodnje vrednosti, na primer projekcije prihodkov ali prodaje. Za izdelavo takšnih ocen organizacije včasih uporabljajo tehnologijo rudarjenja podatkov pri oblikovanju napovednih modelov. Ko razumete osnovne koncepte in nekatere podrobnosti, lahko začnete uspešno uporabljati napovedne zmogljivosti storitev SQL Server Analysis Services (SSAS).
Obstajajo različni pristopi k napovedovanju. Na primer, spletno mesto Metode napovedovanja (forecastingmethods.org) opredeljuje različne kategorije metod napovedovanja, vključno s priložnostnimi (drugače imenovanimi ekonomsko -matematične), strokovnim modeliranjem (subjektivno), časovnimi vrstami, umetno inteligenco, trgom napovedi, verjetnostnim napovedovanjem, modeliranjem napovedi, in napovedovanje metod na podlagi referenčnih razredov. Spletna stran Načela napovedovanja (www.forecastingprinciples.com) ponuja drevesni pogled na metode, ki ločujejo predvsem subjektivne metode (tj. Metode, ki niso na voljo za kvantitativno analizo) in statične (tj. Metode, ki so na voljo, če so na voljo ustrezni numerični podatki) . V tem članku se bom osredotočil na napovedovanje časovnih vrst, vrsto statičnega pristopa, pri katerem zbrani podatki zadostujejo za napovedovanje kazalnikov.
Napovedovanje časovnih vrst predvideva, da podatki iz preteklosti pomagajo razložiti prihodnje vrednosti. Pomembno je razumeti, da v nekaterih primerih imamo opravka s podrobnostmi, ki se ne odražajo v zbranih podatkih. Na primer, pojavil se bo nov konkurent, ki bi lahko negativno vplival na prihodnje zaslužke ali hitre spremembe delovne sile, kar bi lahko vplivalo na stopnjo brezposelnosti. V takih situacijah napovedovanje časovnih vrst morda ni edini pristop. Pogosto se za najbolj natančne napovedi kombinirajo različni pristopi napovedovanja.
Časovna vrsta je zbirka vrednosti, pridobljenih v določenem časovnem obdobju, običajno v rednih časovnih presledkih. Pogosti primeri vključujejo prodajo na teden, četrtletne izdatke in stopnjo brezposelnosti po mesecih. Podatki o časovnih vrstah so predstavljeni v grafični obliki s časovnimi intervali vzdolž osi x grafa in vrednostmi vzdolž osi y, kot prikazuje slika 1.
Pri obravnavi, kako se vrednost spreminja iz enega obdobja v drugo in kako predvideti vrednosti, je treba upoštevati, da imajo podatki časovnih vrst nekatere pomembne značilnosti.
Tako imate z identifikacijo trenda, prekrivanjem linije trenda na izhodiščno vrednost in določanjem sezonske komponente, ki se lahko pojavi pri analizi podatkov, model napovedovanja, ki ga lahko uporabite za predvidevanje vrednosti:
Napovedana vrednost = izhodiščna vrednost + trend + sezonska komponenta
Edini način za določitev izhodišča in trenda je uporaba regresijske metode. Beseda "regresija" se tukaj nanaša na upoštevanje razmerja med spremenljivkami. V tem primeru obstaja povezava med neodvisno spremenljivko časa in odvisno spremenljivko števila brezposelnih. Upoštevajte, da se razlagalna spremenljivka včasih imenuje napovednik.
Za uporabo metode regresije uporabite orodje, kot je Microsoft Excel. Na primer, lahko izvedete samodejno štetje v Excelu in dodate črto trenda v grafikon časovnih vrst z uporabo menija Trendline na zavihku Postavitev orodij za grafikone ali zavihka Postavitev orodij vrtilnih grafikonov v podoknu Excel 2010 ali Excel 2007. Na sliki 1 sem dodal ravno linijo trenda z izbiro načina Linearna linija trenda v meniju Trendline. Nato sem v meniju Trendline izbral Več možnosti trenda, nato pa prikaz enačbe na grafikonu in prikaz vrednosti R na kvadrat pri možnostih grafikona, glej sliko 3.
.jpg) |
| Slika 3: Možnosti trendov v Excelu |
Ta postopek prilagajanja trendne črte nakopičenim podatkom se imenuje linearna regresija. Kot lahko vidimo na sliki 1, se linija trenda izračuna po enačbi, kjer se določita osnovna raven (8248,8) in trend (104,67x):
y = 104,67x + 8248,8
Linijo trenda si lahko predstavljate kot vrsto povezanih koordinat osi x-y, kamor lahko vključite časovni razpon (to je os x), da dobite vrednost (os y). Excel določi "najboljšo" linijo trenda z uporabo metode najmanjših kvadratov (definirano kot R² na sliki 1). Linija najmanjših kvadratov je črta, ki zmanjšuje kvadratno navpično razdaljo od vsake točke na trendni liniji do ustrezne točke na črti. RMS vrednosti vam omogočajo, da ugotovite, da se odstopanja nad ali pod dejansko črto ne izničijo. Na sliki 1 vidimo, da je R² = 0,5039, kar pomeni, da linearno razmerje pojasnjuje 50,39% spremembe statistike brezposelnosti skozi čas.
Iskanje natančne linije trenda v Excelu pogosto vključuje poskuse in napake, skupaj z vizualnim pregledom. Na sliki 1 ravna črta trenda ni najbolj primerna. Excel ponuja druge možnosti trendne črte, ki jih vidite na sliki 3. Na sliki 4 sem dodal črto drsečega povprečja s štirimi obdobji, ki je narisana na podlagi aritmetičnega povprečja trenutnega in zadnjega nastavljenega obdobja v časovnem nizu.
Prav tako sem dodal polinomsko linijo trenda z uporabo algebrske enačbe za risanje črte. Upoštevajte, da ima polinomska linija trenda vrednost R² 0,9318, kar kaže na najboljše razmerje v smislu odnosa med neodvisnimi in odvisnimi spremenljivkami. Višja vrednost R² pa ne pomeni nujno, da bo linija trenda zagotovila kakovost napovedovanja. Obstajajo še druge metode za natančne napovedi, ki jih bom na kratko opisal v nadaljevanju. Nekatere možnosti za linijo trenda v Excelu (na primer linearna, polinomska črta trenda) vam omogočajo napovedi tako naprej kot v nasprotni smeri, ob upoštevanju števila obdobij, z narisom dobljenih vrednosti na grafikonu. Nekaterim se lahko izraz "napoved v nasprotni smeri" zdi nenavaden. To je najbolje ponazoriti s primerom. Recimo, da je nov dejavnik - hitro povečanje števila delovnih mest v javnem sektorju (npr. Delovna mesta domovinske obrambe v začetku leta 2000, začasni delavci ameriškega urada za popis prebivalstva) - sprostil hiter padec brezposelnosti. Za več mesecev morate napovedati stopnjo rasti sektorja novih delovnih mest v nasprotni smeri, nato pa ponovno izračunati stopnjo brezposelnosti, da boste prišli do zmernega merila sprememb.
Enačbo trendne črte lahko uporabite tudi za izračun vrednosti v perspektivi. Na sliki 5 sem dodal 6-mesečno napovedno polinomsko linijo trenda, tako da sem podatke za zadnjih 6 mesecev (to je od aprila do septembra 2012) najprej odstranil iz prvotne časovne vrste.
Če zaslon 5 primerjate z zaslonom 1, boste opazili, da imajo polinomske napovedi naraščajoči trend, ki ne ustreza trendu navzdol (trendu) dejanske časovne vrste.
O regresiji je treba omeniti dve pomembni točki.
Sezonska komponenta v strukturi časovnega niza se običajno kaže bodisi z dnem v tednu bodisi z dnem v mesecu ali z mesecem v letu. Kot je navedeno zgoraj, se število brezposelnih v Združenih državah v določenem koledarskem letu običajno povečuje in zmanjšuje. To velja tudi, ko gospodarstvo raste, kot prikazuje slika 2. Z drugimi besedami, za natančno napoved morate upoštevati sezonsko komponento. Eden pogost pristop je uporaba sezonskega glajenja. V praktičnem napovedovanju časovnih vrst: Priročnik, druga izdaja (CreateSpace Independent Publishing Platform, 2012), avtor Galit Shmuely priporoča uporabo ene od treh metod:
Izhodišče in trend sta določena pri izračunu napovedi na podlagi zglajene časovne vrste. Po želji lahko sezonsko komponento ali prilagoditev ponovno uporabimo za napovedane vrednosti na podlagi začetnih vrednosti sezonskih faktorjev pri uporabi Holt-Winters metode. Če želite videti, kako se sezonskost izračuna v Excelu, v spletu poiščite »Zimska metoda v Excelu«. Za obsežno razlago Holt-Wintersove metode glejte Wayne L. Winstonov Microsoft Office Excel 2007: Analiza podatkov in poslovno modeliranje, druga izdaja (Microsoft Press, 2007).
V številnih paketih za rudarjenje podatkov, kot je SSAS, algoritmi za napovedovanje časovnih vrst samodejno upoštevajo sezonske variacije z merjenjem sezonskih razmerij in njihovo vključitvijo v model napovedovanja. Morda pa boste želeli nastaviti namige o vzorcu sezonskih sprememb.
Kot smo že omenili, prvotni model (z uporabo metode najmanjših kvadratov) ne zagotavlja nujno natančnosti napovedi. Najboljši način za preverjanje natančnosti napovednih ocen je, da časovno vrsto razdelite na dva niza podatkov, enega za izdelavo (tj. Usposabljanje) modela in drugega za preverjanje. Podatkovni niz bo najnovejši del prvotnega nabora podatkov in v idealnem primeru zajema čas, ki je enak napovedni časovnici za prihodnost. Za preverjanje (potrditev) modela se predvidene vrednosti primerjajo z dejanskimi vrednostmi. Upoštevajte, da je po potrditvi modela mogoče obnoviti model z uporabo celotne časovne vrste, zato je za napovedovanje prihodnjih vrednosti meritev priporočljivo uporabiti najnovejše dejanske vrednosti.
Pri merjenju natančnosti napovednega modela se običajno pojavita dve vprašanji: kako določiti natančnost napovedne ocene in koliko zgodovinskih podatkov uporabiti za usposabljanje modela.
Kako določiti natančnost napovedne ocene? V nekaterih scenarijih predvidene vrednosti nad dejanskimi vrednostmi morda niso zaželene (na primer v projekcijah naložb). V drugih primerih imajo lahko napovedane vrednosti pod dejanskimi vrednostmi uničujoče posledice (na primer napoved najnižje zmagovalne cene ponudbe za postavko na dražbi). Toda v primerih, ko želite izračunati rezultat za vse napovedi (ni pomembno, ali so predvidene vrednosti višje ali nižje od dejanskih vrednosti), lahko začnete s količinsko napako v ločeni napovedi z uporabo definicije:
napaka = predvidena vrednost - dejanska vrednost
S to definicijo napake obstajata dve priljubljeni metodi za merjenje natančnosti: povprečna absolutna napaka, to je povprečna absolutna napaka (MAE) in povprečna absolutna odstotna napaka (MAPE). Pri metodi MAE se absolutne vrednosti napak napovedi seštejejo in nato delijo s skupnim številom napovedi. Metoda MAPE izračuna povprečno absolutno odstopanje od napovedi kot odstotek. Za primere dela s temi in drugimi metodami za merjenje kakovosti napovednih ocen, predlogo Excel (z vzorčnimi napovednimi podatki in faktorji natančnosti), glejte spletno stran Predloga za diagnostiko meritev povpraševanja (demandplanning.net/DemandMetricsExcelTemp.htm).
Koliko zgodovinskih podatkov je treba uporabiti za usposabljanje modela? Pri delu s časovno vrsto, ki sega daleč nazaj, boste morda želeli v svoj model vključiti vse zgodovinske podatke. Vendar včasih dodatna zgodovina ne izboljša natančnosti napovedovanja. Zgodovinski podatki lahko celo izkrivijo napoved, če se razmere v preteklosti bistveno razlikujejo od sedanjih (na primer sestava delovne sile je drugačna zdaj in v preteklosti). Nisem naletel na nobeno posebno formulo ali praktično metodo, ki bi mi povedala, koliko zgodovinskih podatkov naj vključim, zato predlagam, da začnem s časovnimi vrstami, ki so nekajkrat večje od napovedanih časovnih intervalov, in nato preverim točnost. Nato poskusite zaokrožiti številko zgodovine navzgor ali navzdol in znova zagnati test.
Napovedovanje časovnih vrst se je v sistemu SSAS prvič pojavilo leta 2005. Za izračun predvidenih vrednosti je algoritem Microsoftove časovne vrste uporabil en sam algoritem, imenovan avtoregresivno drevo s navzkrižno napovedjo (ARTXP) ali avtoregresivno drevo s navzkrižnim predvidevanjem. ARTXP združuje avtoregresivno metodo z rudarjenjem podatkov v drevesu odločitev, tako da se lahko enačba napovedi spremeni (kar pomeni razdelitev) na podlagi določenih meril. Na primer, model napovedovanja bo zagotovil boljše prileganje (in boljšo natančnost napovedi), če najprej delite po datumu, nato pa na podlagi vrednosti pojasnjevalne spremenljivke, kot prikazuje slika 6.
.jpg) |
| Slika 6: Primer odločitvenega drevesa ARTXP v SSAS |
V SSAS 2008 je Microsoftov algoritem časovnih vrst poleg ARTXP začel uporabljati algoritem, imenovan avtoregresivno integrirano drseče povprečje (ARIMA), integrirano drseče povprečje z avtoregresijo, za izračun dolgoročnih napovedi. ARIMA velja za industrijski standard in jo lahko razumemo kot kombinacijo avtoregresivnih procesov in modelov drsečega povprečja. Poleg tega analizira zgodovinske napake napovedi za izboljšanje modela.
Algoritem Microsoft Time Series privzeto združuje rezultate algoritmov ARIMA in ARTXP za doseganje optimalnih napovedi. Če želite, lahko to funkcijo prekličete. Oglejmo si dokumentacijo SQL Server Books Online (BOL):
"Algoritem usposablja dva različna modela istih podatkov: en model uporablja algoritem ARTXP, drugi pa algoritem ARIMA. Algoritem nato združi rezultate obeh modelov, da razvije najboljšo napoved, ki zajema spremenljivo število časovnih rezin. Ker je algoritem ARTXP bolj primeren za kratkoročne napovedi, ga je priporočljivo uporabiti na začetku serije napovedi. Če pa bodo časovni zamiki, potrebni za napovedovanje, v prihodnosti, je algoritem ARIMA bolj smiseln. "
Pri delu s napovedovanjem časovnih vrst v sistemu SSAS morate upoštevati naslednje:
V tem članku sem vam predstavil osnove napovedovanja časovnih vrst. Zajeli smo tudi nekatere podrobnosti osnovnih algoritmov, da ne ovirajo obdelave časovnih vrst. Kot naslednji korak predlagam, da obvladate orodja za napovedovanje časovnih vrst s SSAS. Vzorec bi bil projekt, ki uporablja podatke o brezposelnosti, navedene v tem članku. Nato si lahko ogledate Vadnico za vmesno rudarjenje podatkov (storitve za analizo - rudarjenje podatkov) na spletnem mestu TechNet na naslovu technet.microsoft.com/en-us/library /cc879271.aspx.
Tehnologije poslovne inteligence (BI), kot je OLAP, so se v zadnjem desetletju začele široko uporabljati. Hkrati je Microsoft začel promovirati drugo tehnologijo BI, rudarjenje podatkov, v priljubljenih orodjih, kot sta Microsoft SQL Server in Microsoft Excel. Tehnologija podatkovnega rudarjenja pa še ni prevzela vodstva. Zakaj? Medtem ko večina ljudi lahko hitro dojame temeljne koncepte rudarjenja podatkov, so osnovne podrobnosti algoritmov neločljivo povezane z matematičnimi koncepti in formulami. Obstaja velika "razlika" med visoko stopnjo abstraktnega razumevanja in podrobno izvedbo. Zato strokovnjaki IT in industrijski odjemalci na rudarjenje podatkov gledajo kot na črno škatlo, kar pa ne prispeva k širokemu sprejetju tehnologije. Ta članek je moj poskus zmanjšanja "neskladja" pri napovedovanju časovnih vrst.
V glavnem članku podatki za grafe temeljijo na podatkih o delovno aktivnem prebivalstvu, ki so jih objavile ZDA. Urad za statistiko dela (http://www.bls.gov/). BLS objavlja podatke o brezposelnosti na podlagi mesečne raziskave ameriškega urada za popis prebivalstva (BLS), ki ekstrapolira skupno število zaposlenih in brezposelnih oseb. BLS uporablja formulo:
Stopnja brezposelnosti = brezposelna / (brezposelna + zaposlena)
Omeniti velja, da mediji pri stopnji brezposelnosti običajno navajajo izenačen sezonski koeficient. Sezonsko prilagajanje se izvaja s splošnim modelom, imenovanim avtoregresivno integrirano drseče povprečje (ARIMA). To je v bistvu isti algoritem, ki se uporablja v številnih paketih za rudarjenje podatkov za napovedovanje časovnih vrst, vključno s storitvami za analizo SQL Server (SSAS). Za več informacij o modelu ARIMA, ki ga uporablja BLS, obiščite spletno stran programa sezonskega prilagajanja X-12-ARIMA (www.census.gov/srd/www/x12a/). Upoštevajte, da sem pri tipični zasnovi tega članka uporabil sezonske in nesezonsko prilagojene vrednosti.









